Пару слов о себе¶
- Шестаков Андрей
- 2011-2016: Разработчик-исследователь, компания Forecsys
- 2016-2018: Программист-математик, департамент рекламных технологий Mail.Ru
- 2018+: Руководитель группы предиктивной аналитики, департамент рекламных технологий Mail.Ru
Мотивация¶
Мотивация¶

Data everywhere¶
- Социальные сети
- Онлайн-сервисы
- Мобильные устройства
- Фитнес-трекеры
- Интернет-вещей
- ...
- Накапливается очень много данных из всевозможных источников
- Хочется их не просто хранить, но и извлекать из них знания, закономерности
Мотивация¶
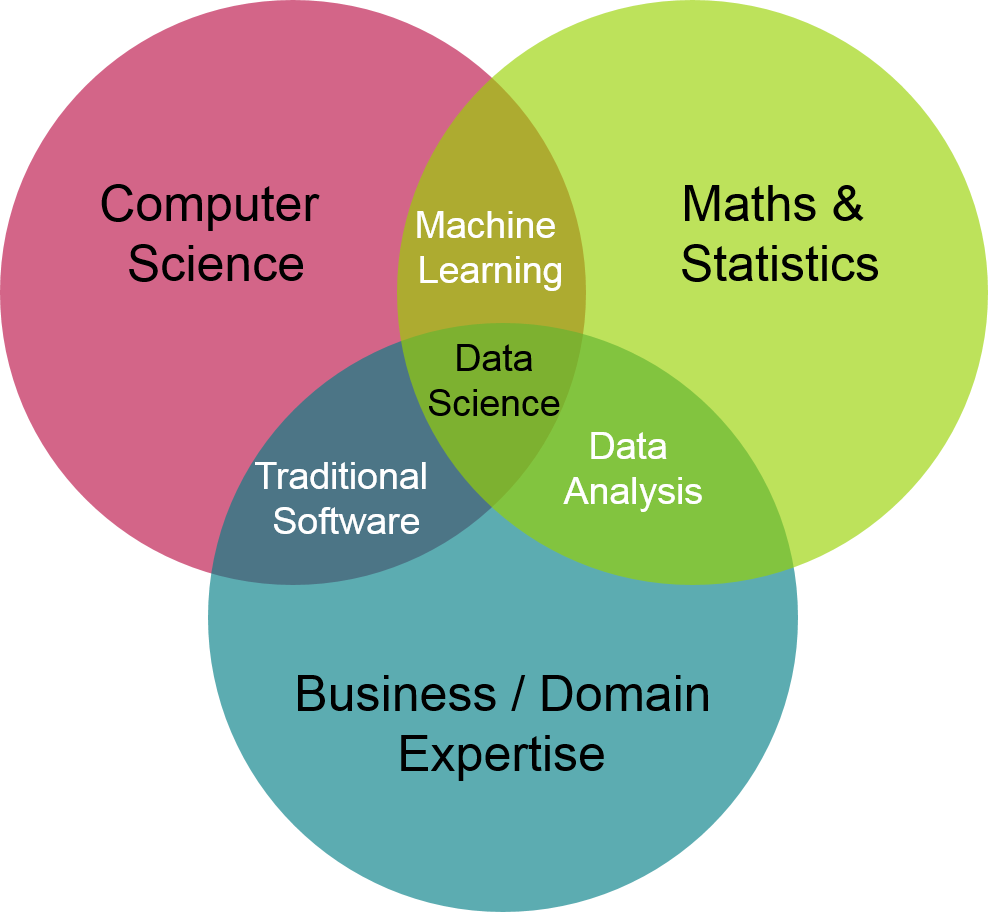
Мотивация¶
- Data scientist сейчас крайне востребованная профессия
- Data scientist использует методы машинного обучения чтобы извлекать знания из данных

Machine learning?¶
- В широком смысле, машинное обучение – набор методов, позволяющий обучать вычислительные системы решать определенную задачу без явного программирования
Простые примеры¶
- Фильтрация спама
- если отправитель часто фигурирует в черных списках -> спам
- если письмо содержит 'специальное предложение' и отправитель ранее не встречался во "входящих" -> спам
- ...
- Фильтрация машенических операций
- если операции за последние 5 минут содержат очень маленьие и большие суммы - фрод
- если операция по этому mcc регулярно просиходила ранее - не фрод
- ...
- Методы машинного обучения постараются сами
- определить ключевые зависимости в размеченных данных
- найти структуру в неразмеченных данных
Обучение по прецедентам¶
- Множество объектов $𝑂$
Каждому объекту $o \in O$ можно поставить в соответствие набор признаков $(x,y)$, где
- $x \in X$ - вектор описательных признаков (предикторов)
- $y \in Y$ - целевой признак
Существует неизвестная зависимость $f:X \rightarrow Y$
- Задачи:
- Используя конечный набор примеров $(x,y)$, обучить модель $a(x) = \hat{y}$, аппроксимирующую $f$
- Применить алгоритм $a(x)$ на новых объектах (prediction)
- Понять, как именно $x$ влияют на $y$ (inference, interpretation)
Простой пример¶

- Эти признаки очевидно как-то влияют на цену ($f: X \rightarrow Y$)
- Составим модель, которая будет принимать на входе эти признаки: $$a(x) = a(total\_area, nmbr\_of\_bedrooms, house\_age) = \hat{y}$$
- Пусть она будет иметь линейный вид: $$a(x) = w_0 + w_1\cdot total\_area + w_2 \cdot nmbr\_of\_bedrooms + w_3 \cdot house\_age$$
- Обучение - найти коэффициенты $w_0,\dots, w_3$, минимизирующие ошибку на обучающей выборке
Простой пример 2¶
| Отзыв | Тональность |
|---|---|
| Преподаватели сильные, отвечали на вопросы оперативно (по большей части), что приятно — даже в выходные и поздно вечером. | +1 |
| Здорово, что были трансляции по доп.материалу (обработка текстов). Хотелось бы побольше такого. От Петра много лайфхаков по обработке текста узнала. Спасибо ему! | +1 |
| Очень жаль, что мало рассказали про Deep Learning | -1 |
- Какие признаки будут здесь?
- Как будет выглядеть линейная модель?
Анализ электората¶
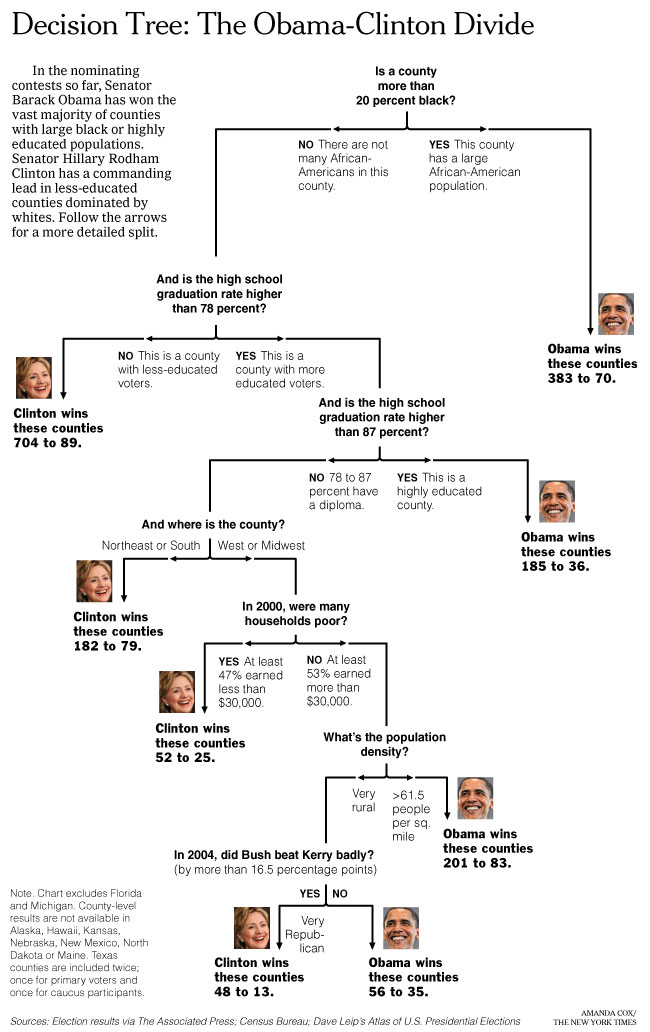
А теперь ответьте мне на один вопрос..¶
Вернемся к нашему курсу¶
Что будет на курсе¶
- Вникнем в основы машинного обучения
- кластеризация
- классификация
- регрессия
- Научимся загружать и предобрабатывать различные типы данных
- тексты
- сетевые структуры
- Курсовой проект
Чего на курсе не будет¶
- Deep Neural Nets, Recurrent Nets, GANS =(
- Reinforcement Learning =[
- Time Series Forecasting =\
Основные типы задач и типы признаков¶
Основные моменты¶
- Как сформулировать задачу?
- Как выбирать/составлять признаковое описание объектов?
- Как определяется и обучается $a(x)$?
- Как оцениваеться качество $a(x)$?
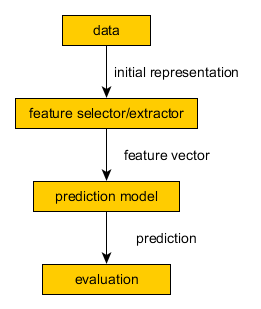
General Modelling Pipeline¶
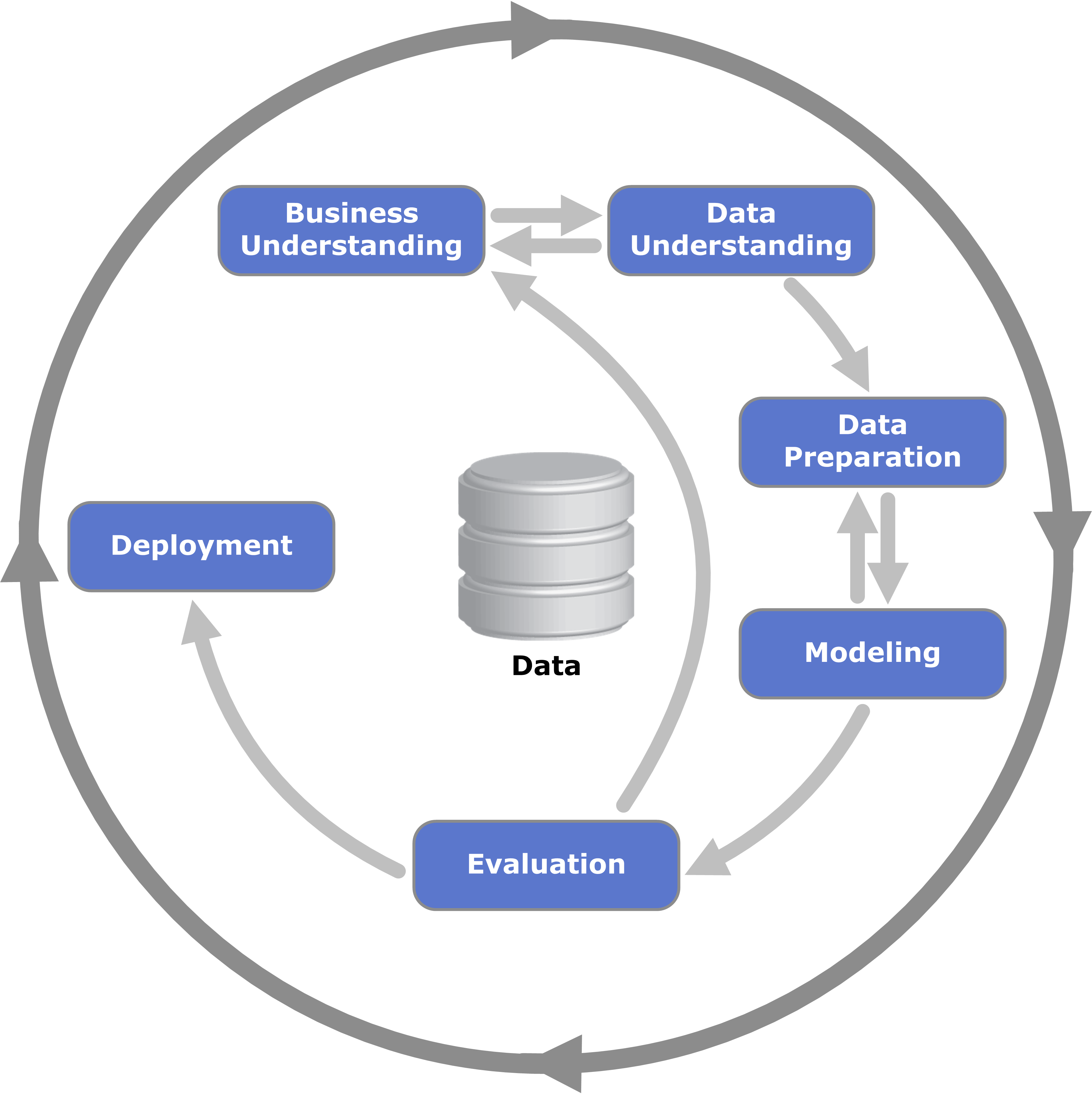
CRISP DM¶
Основные типы задач¶
- Обучение с учителем (Supervised Learning)
- Модель подстаивается под целевой признак $y$
- Классификация:
- $Y=\{−1, +1\}$ (Bad, Good в кредитном скорринге)
- $Y=\{1, 2, 3, \dots, C\}$ (Типизация автивности)
- Регрессия: $Y \in \mathbb{R}$ (оценка стоимости жилья)
- Ранжирование: $Y \in \mathbb{R}$ (оценка релевантности запроса)
- Обучение без учителя (Unsupervised Learning)
- Кластеризация (сегментация клиентов магазина)
- Уменьшение признаковго пространства (составление тематик интересов)
- Выявление ассоциативных правил
- Обучение с подкреплением (Reinforcement Learning)
In [3]:
YouTubeVideo('V1eYniJ0Rnk', width=700, height=600)
Out[3]:
Типы признаков¶
Модели понимают только числа! При этом каждый тип модели понимает их по своему
Garbage in - garbage out
- Бинарные - $x_i\in \{0, 1\}$
- Категориальные - $|x_i|<\infty$
- Порядковые - $|x_i|<\infty$
- Вещественные - $x_i \in \mathbb{R}$
Примеры¶
Задача "кредитный скоринг"¶
- Объект — заявка на выдачу кредита банком
- Ответ — вернет ли клиент кредит
- Тип задачи?
Задача "кредитный скоринг" - признаки¶
- Бинарные: пол, наличие телефона, и т.д.
- Категориальные: место жительства, профессия, семейный статус, работодатель, и т.д.
- Порядковые: образование, должность, и т.д.
- Вещественные: возраст, зарплата, стаж работы, доход семьи, сумма кредита, и т.д.
Задача "предсказание оттока клиентов"¶
- Объект — абонент в определенный момент времени
- Ответ — уйдет или не уйдет в следующем месяце
- Тип задачи?
Задача "предсказание оттока клиентов" - признаки¶
- Бинарные: корпоративный клиент, подключенные услуги, и т.д.
- Категориальные: регион проживания, тарифный план, и т.д.
- Вещественные: длительность разговоров, количество СМС, частота оплаты, объем трафика, и т.д.
Задача "категоризация новостной статьи"¶
- Объект — текст статьи
- Ответ — набор тегов-категорий
- Тип задачи?
Задача "категоризация новостной статьи" - признаки¶
- Бинарные: наличие тех или иных ключевых слов
- Категориальные: регион
- Вещественные: количество ссылок на другие статьи соответствующих категорий
Задача "оценка стоимости автомобиля"¶
- Объект — автомобиль
- Ответ — стоимость в рублях
- Тип задачи?
Задача "оценка стоимости автомобиля" - признаки¶
- Бинарные: первичный или вторичный рынок, тюнинг
- Категориальные: цвет, коробка передач, тип кузова...
- Вещественные: пробег, объем двигателя, мощность двигателя..
Обобщающая способность¶
Обобщаяющая способность¶
- Обучающая выборка (Training Set, Development Sample) - набор объектов с признаками, по которому алгоритм будет учиться находить зависимости в данных
Обобщающая способность алгоритма¶
- Можно построить алгоритм с идеальным качеством на обучающей выборке
- Profit???
- Nope...
- Важно понимать, насколько хорошо работает алгоритм на объектах, которые он ранее не видел
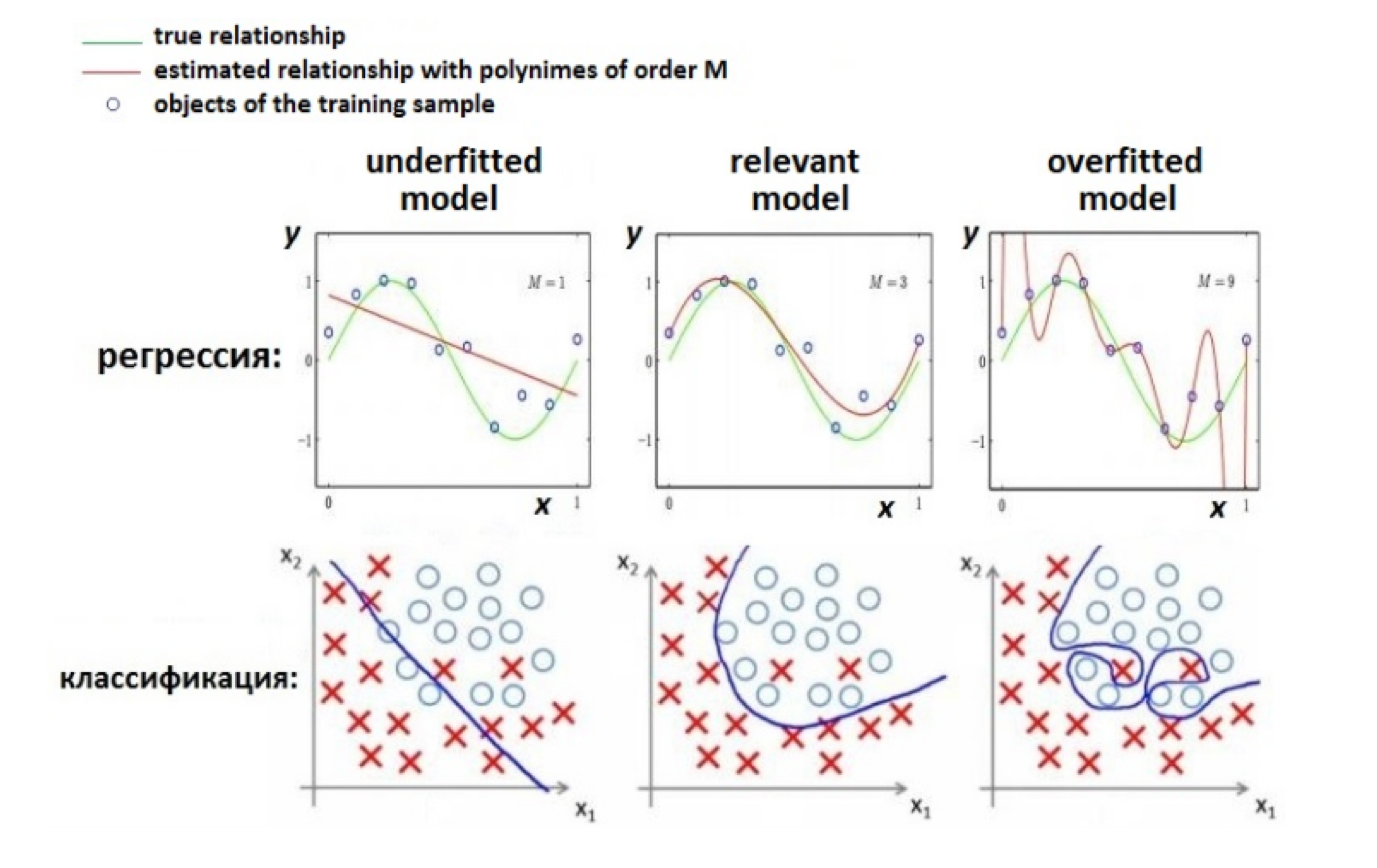
- Недообучение (underfitting) – модель сильно упростила искомую зависимость
- Переобучение (overfitting) – модель подогналась даже под шум в данных
Обобщающая способность алгоритма¶
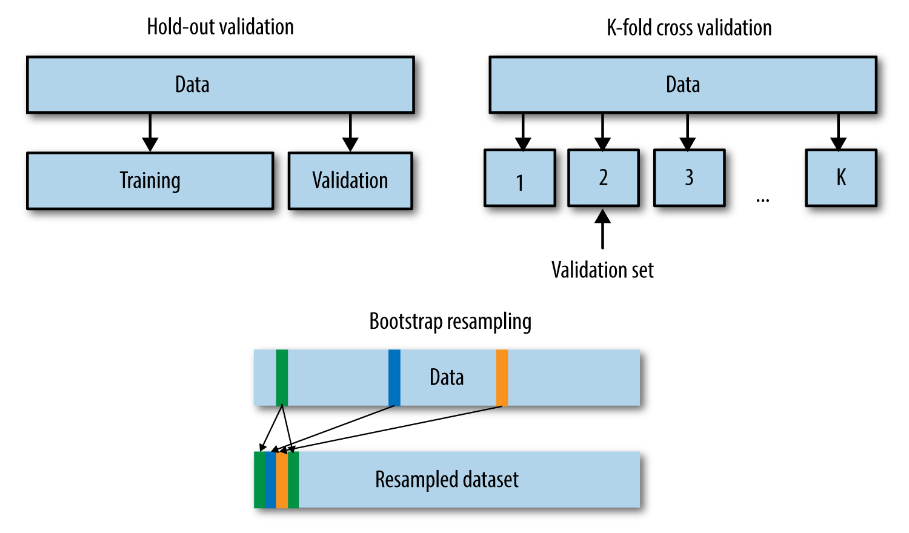
Оценка обобщающей способности (оффлайн)¶
- Выделяется валидационная выборка (Validation Set) - выборка объектов, которая принадлежит той же генеральной совокупности, что и обучающая выборка. На объектах из этой выборки алгоритм не обучался.
Меры качества классификации¶
Меры качества классификации¶
- Как правило, классификаторы выдают не просто предсказанную метку класса, но и степень уверенности в ней
- Основные меры качества
- Accuracy
- Precision, Recall, F-measure
- ROC-AUC, PR-AUC Gini-index, Model-lift
- Log-loss
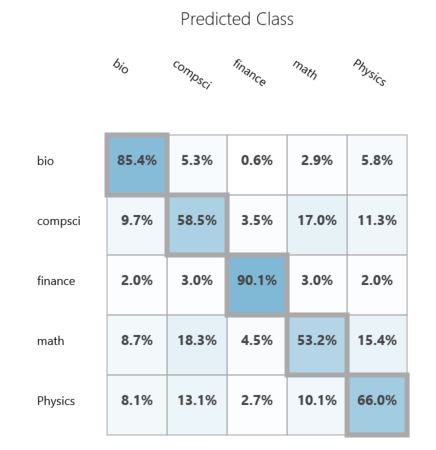
Матрица перемешивания¶
Матрица перемешивания $M=\{m_{ij}\}_{i,j=1}^{C}$ показывает количество объектов класса $с_{i}$, которые были отнесены классификатором к классу $с_{j}$.
Матрица перемешивания (2 класса)¶
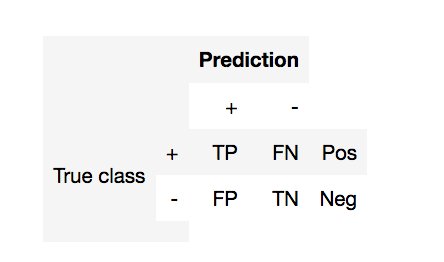
- TP (true positive) - Верное предсказание (+1)
- FP (false positive) - Ошибка первого рода (ложная тревога)
- FN (false negative) - Ошибка второго рода (пропуск цели)
- TN (true negative) - Верное предсказание (-1)
- Pos (Neg) - Общее количество +1 и -1
Меры на основе матрицы перемешивания¶
- $ \text{accuracy} = \frac{TP + TN}{Pos+Neg}$
- $ \text{error rate} = 1 -\text{accuracy}$
- $ \text{recall} =\frac{TP}{TP + FN} = \frac{TP}{Pos}$ - (полнота)
- $ \text{precision} =\frac{TP}{TP + FP}$ - (точность)
- $ \text{F}_\beta \text{-score} = \frac{1+\beta^2}{\frac{1}{Recall} + \frac{1}{\beta^2 Precision}} = (1 + \beta^2) \cdot \frac{\mathrm{precision} \cdot \mathrm{recall}}{(\beta^2 \cdot \mathrm{precision}) + \mathrm{recall}}$
- почему не среднее или максимум?
- Можно ли посчитать эти меры для многоклассовой классификации?
In [8]:
fig = interact(demo_fscore, beta=FloatSlider(min=0.1, max=5, step=0.3, value=1))
Меры качества на основе уверенности классификатора¶
ROC кривая¶
- Выбор порога классификации - отдельная большая задача
- Можно ли как-то обойтись без него и сравнить неколько моделей?
- ROC кривая - показывает зависимость между TPR (верным предсказанием) и FPR (ложным срабатыванием)
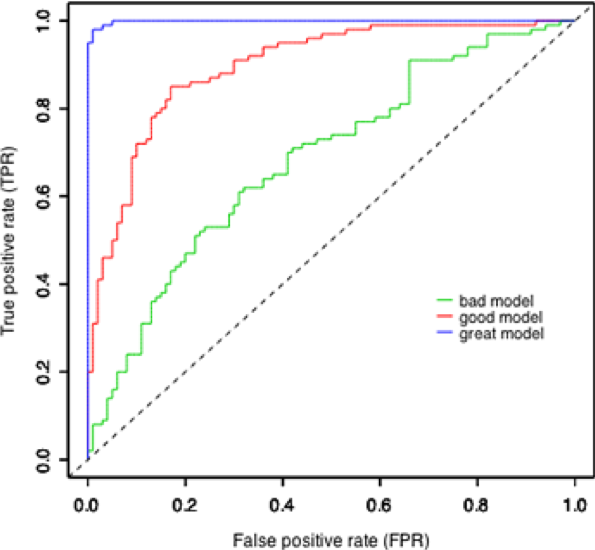
ROC кривая¶
- Классификатор $a(x)$ возвращает степень принадлежности к классу "+1" - score(x).
- Упорядочим объекты по убыванию score(x)
- Смотрим сверху вниз
- Если объект принадлежит классу "+1" - сдвиг вверх на $1/Pos$
- Если объект принадлежит классу "-1" - сдвиг вправо на $1/Neg$
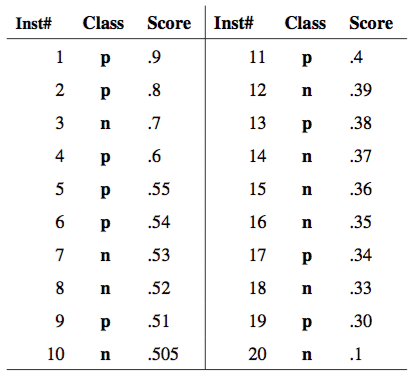
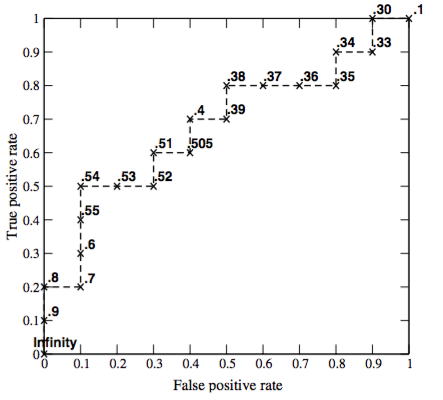
Как сравнивать ROC-кривые?¶
ROC-AUC¶
Площадь под ROC кривой
AUC$\in[0,1]$
- AUC = 0.5 - случайный классификатора
- AUC = 1 - идеальный классификатор
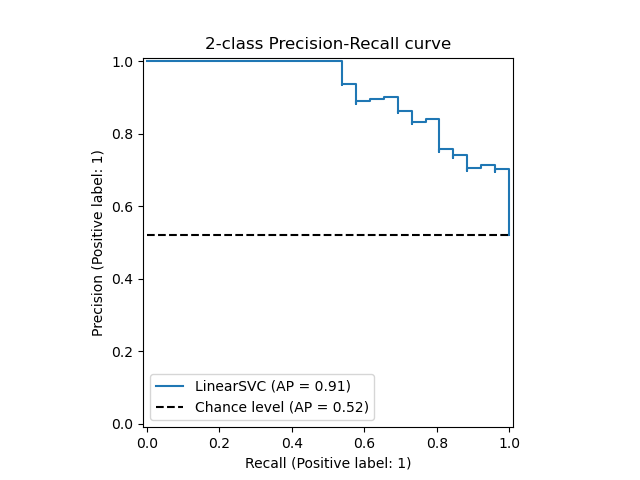
Precision-Recall Кривая¶
- Строится аналогичным образом, но по осям Precision и Recall для разных порогов
Резюме¶
- Машинное обучение позволяет находить зависимости в данных
- Основные типы задач - классификация, регрессия, ранжирование
- Оценка качества с помощью кросс-валидации и отложенной выборки