- Тематическое моделирование - одно из современных направлений тематического анализа, активно развивающегося с конца 90-х годов.
- Идея ТМ схожа с идеей кластеризации - документы могут быть причислены к отпределенным тематикам, которые формируются на основе слов, из которых они состоят
- Хочется на выходе иметь тематическое представление каждого документа, и, желательно интерпретируемое представление каждой темы
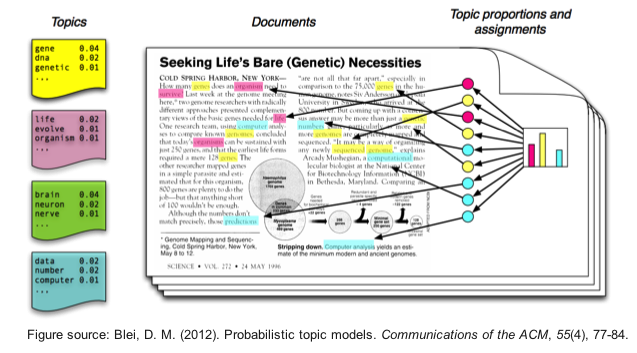
Приложения¶
- Тематический поиск
- Суммаризация и аннотирование текстовых документов
- Динамика тематик в предметной области на протяжении времени
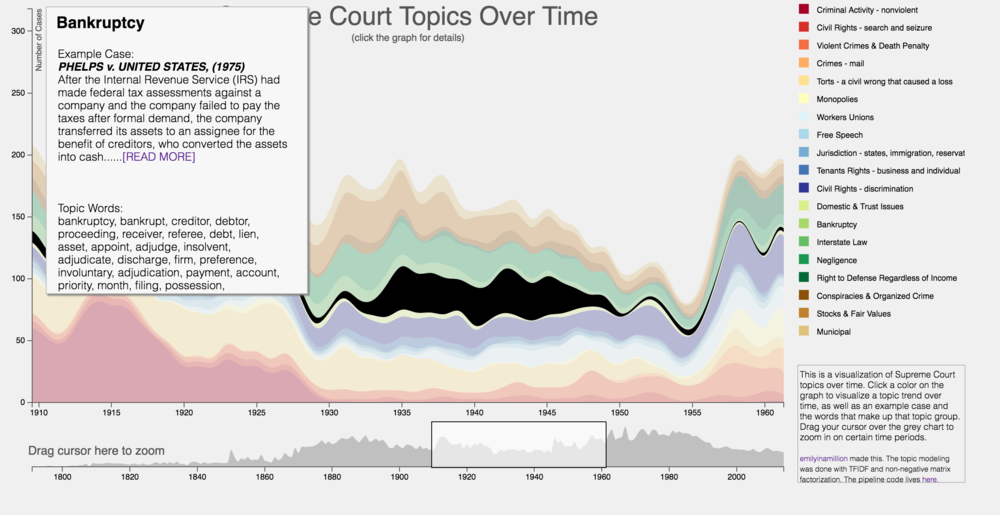
Предположения¶
- Порядок слов в документе и порядок документов в корпусе не важен (модель мешка слов)
- Каждый терм в документе связан с некоторой темой
- Документы и слова - наблюдаемые значения, тематики - скрытые значения
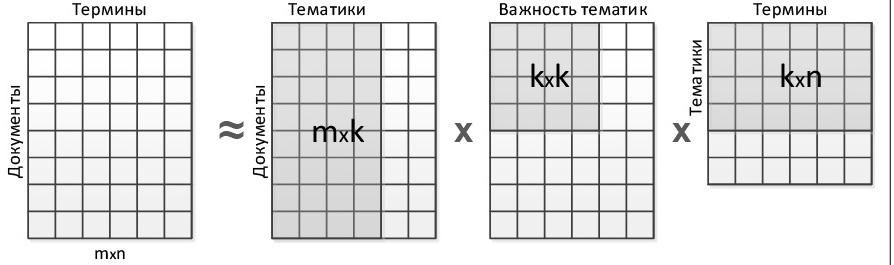
Преимущества
- Все просто
- Можно находить похожие слова через матрицу $V$ и похожие документы через матрицу $U$
- Есть практика использования LSA для задачи поиска (Latent Semantic Indexing)
Недостатки
- Плохо интерпретируется
Вероятностный латентный семантический анализ (PLSA)¶¶
Вероятностный латентный семантический анализ (PLSA)¶
- Каждый документ задает вероятностное распределение по темам - $p(t|d)$
- Каждая тема задает вероятностное распределение по словам - $p(w|t)$
- Распределение слов по темам не зависит от самого документа (только от его темы) $p(w|d,t) = p(w|t)$
- Документы в нашем корпусе текстов порождаются следующей вероятностной моделью
- Сэмплируем документ $d$
- Для каждого слова $w$ (а точнее места под слово) в документе:
- Сэмплируем тематику $t$ из $p(t|d)$
- Сэмплируем слово $w$ из $p(w|t)$ $$p(w,d) = p(d)p(w|d) = p(d)\sum_t p(w|t)p(t|d)$$
- Мы наблюдаем только $p(w|d)$ и предполагаем, что $$p(w|d) = \sum_t p(w|t)p(t|d) $$
Вероятностный латентный семантический анализ (PLSA)¶
- Максимизируется правдоподобие $$ P(D) = \prod_{d\in D}\prod_{w\in d} p(d,w)^{n_{dw}} $$
Вероятностный латентный семантический анализ (PLSA)¶
- Если бы нам откуда-то были известны присваивания слов темам в каждом документе $p(t|d,w)$, то мы могли бы явно посчитать $p(w|t)$ и $p(t|d)$
Вероятностный латентный семантический анализ (PLSA)¶
- Если бы нам откуда-то были известны присваивания слов темам в каждом документе $p(t|d,w)$, то мы могли бы явно посчитать $p(w|t)$ и $p(t|d)$
- Попытаемся оценить присваивания:
- Получается, если у нас есть $p(w|t)$ и $p(t|d)$, то мы можем оценить присваивания, а затем пересчитать $p(w|t)$ и $p(t|d)$!
- На что похожа эта процедура?
EM-алгоритм¶
- Инициализируем
- количество тем $T$
- $p(w|t)$, $p(t|d)$ (или $\phi_{wt}$, $\theta_{td}$)
- E-шаг
- Считаем $p_{tdw} = p(t|d,w)$
- M-шаг
- Обновляем
- $n_t = \sum\limits_d\sum\limits_w n_{dw} p_{tdw}$ (представленность тематики в корпусе - "количество" документов с тематикой $t$)
- $n_{wt} = \sum\limits_w n_{dw} p_{tdw}$ ("количество" раз, когда слово $w$ относилось к тематике $t$)
- $n_{dt} = \sum\limits_d n_{dw} p_{tdw}$ ("количество" раз, когда документ $d$ относился к тематике $t$)
- $p(w|t) = \frac{n_{wt}}{n_t}$, $p(t|d) = \frac{n_{dt}}{n_t}$
Вероятностный латентный семантический анализ (PLSA)¶
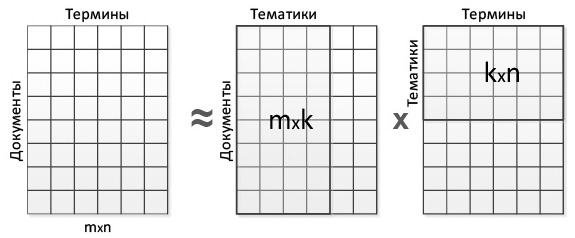
- PLSA так же формулируют в терминах неотрицательной матричной факторизации
Проблемы:
- Неединственность решения
- Нет управления разреженностью матриц $\Phi$ и $\Theta$
- Нет выделения общих тем и других механизмов, логичных в тематическом моделировании
Латентное резмещение Дирихле (LDA)¶
Распределение Дирихле¶
- "Распределение над распределениями"
- $ f(x_{1},\dots ,x_{K};\alpha _{1},\dots ,\alpha _{K})={\frac {1}{\mathrm {B} (\alpha )}}\prod _{i=1}^{K}x_{i}^{\alpha _{i}-1}$
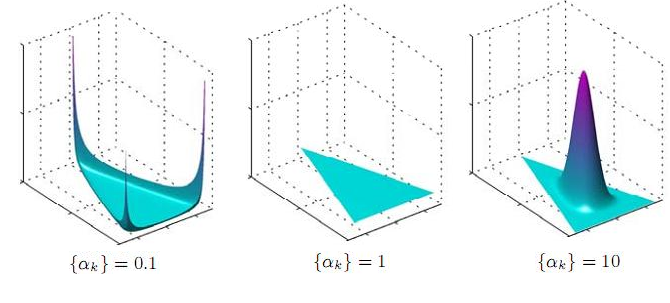
In [11]:
from scipy.stats import dirichlet
alpha = 0.1
components = 10
a = np.empty((components,))
a.fill(alpha)
d = dirichlet(a)
plt.bar(range(components), d.rvs(size=1)[0])
Out[11]:

Латентное резмещение Дирихле (LDA)¶
- На документы и слова накладывается ограничение (регуляризация):
- $\phi_{w} \sim Dir(\lambda)$
- $\theta_{d} \sim Dir(\alpha)$
- Таким образом удается контролировать разреженность матриц $\Phi$ и $\Theta$
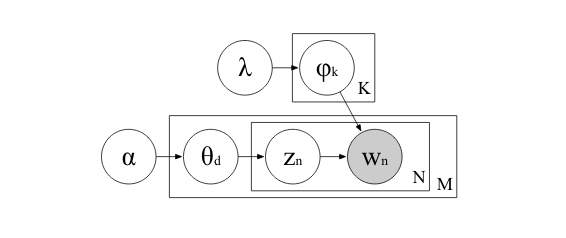
LDA - процесс порождения слов в документе:¶
- Задаем количество тем $T$
- Сэмплируем документ $d$
- Сэмлируем распределение тем в документе: $\theta_{d} \sim Dir(\alpha)$
- Для каждого слова в документе:
- Сэмлируем присваивание слова темe $z_{dw} = Multinomial(\theta_d)$
- Сэмплируем само слово $w$ из $Multinomial(\phi_{z_{dw}})$
- Та же проблема - мы наблюдаем сами документы, а присванивания $z_{dw}$ нам не известны - мы должны их получить
Присваивания тем словам

Распределение слов по темам
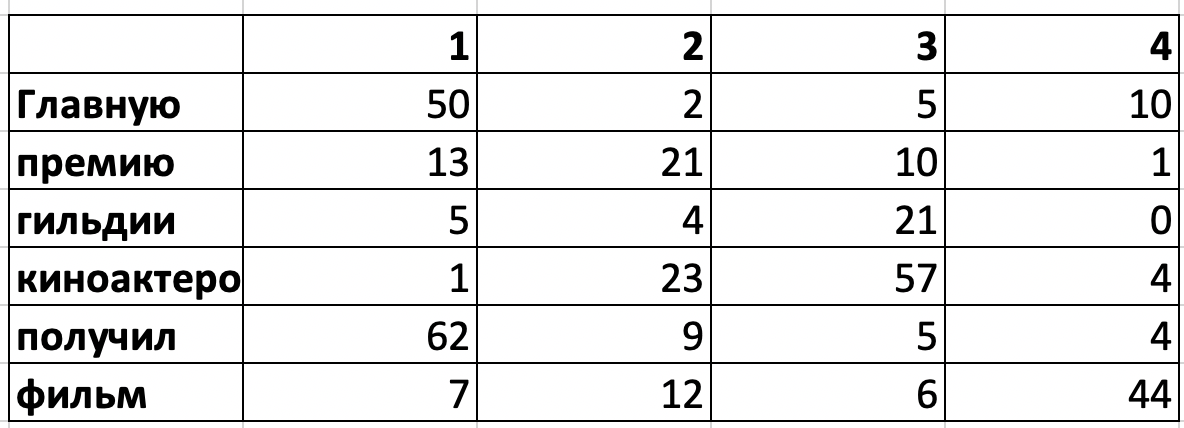
Это не вероятности, но понятно, как из этих данных посчитать вероятности $p(t|d)$ и $p(w|t)$
LDA - обучение (продолжение)¶
Выполняется с помощью Gibbs Sampling (мат выкладки можно найти например тут)
Инициализация: задаем количество тем $T$ и случайно присваиваем каждому слову в каждом документе тему
- Для каждого документа $d$ и каждого слова $w$ в нем считаем
- $p(t|d)$ и $p(w|t)$, $t=1\dots T$
- Выполняем переприсваивание метки темы для слова $w$
- Вычитаем 1 из частоты слова $w$ в теме $z_{dw}$
- Выбираем метку темы $k$ для слова $w$ в документе $d$ с вероятностью $$p(t=k|d,w) \propto p(k|d) p(w|k) = \frac{n_{dk} + \alpha_k}{\sum\limits_t (n_{dt} + \alpha_t)}\frac{n_{wt} + \lambda_w}{\sum\limits_{v\in{V}}(n_{vt} + \lambda_v)}$$
- Продолжаем, пока не выполнится какое-либо правило останова (макс количества операций, слабое изменение правдоподобия, и тп)
ARTM¶
- Более гибкая идеалогия работы с тематическим моделированием
- Основано на PLSA с различными регуляризаторами
- Добавление фоновых тем
- Разреживание предметных тем
- Декорреляция тем
- Работа с модальностями
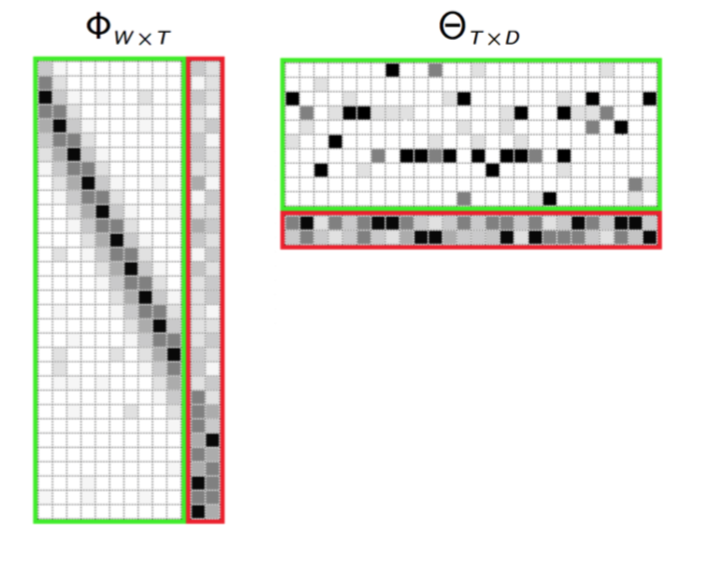 </cetner>
</cetner>