Мотивация¶
- Люди - потребители контента и услуг
- Музыка
- Фильмы
- Книги
- Игры
- Еда
- ...
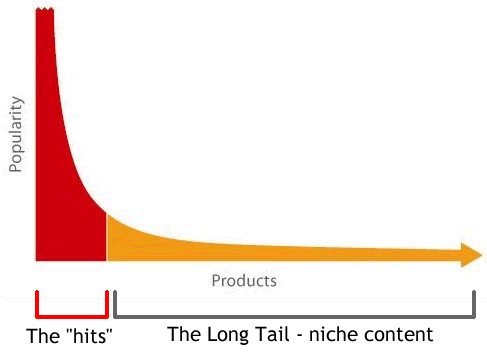
- Но выбор слишком велик..
- Spotify - 30 млн. песен
- Netflix - 20 тыс. фильмов
- Amazon - 500 тыс. книг
- Steam - 20 тыс. игр
Надо как-то фильтровать..
- Можно спросить у друзей (вкусы могут отличаться)
- Можно почитать обзоры (много времени)
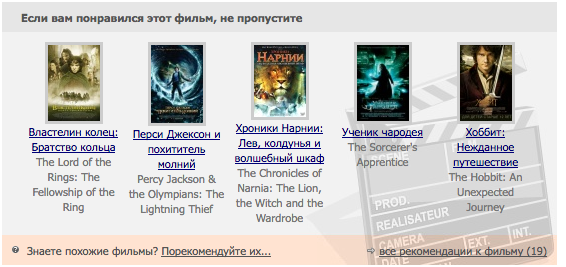
- Автоматическая рекомендательная система!

Long Tail Phenomenon¶

Источники персональных рекомендаций¶
- На основе предпочтений пользователя
- Рассчитывается некоторый "профиль" пользователя, для которого определяются наиболее подходящие товары
- На основе похожих пользователей
- Находим других пользователей с похожими интересами и доставляем рекомендацию
- На основе похожих товоров
- Рекомендуем товары, похожие на те, что мне нравятся
Netflix Prize¶


Постановка проблемы¶
- Пользователи ставят оценку товарам

- Пользователи ставят оценку товарам
- Бинарную
- Количество "звезд"
- Неявную (кол-во потраченого времени\денег)
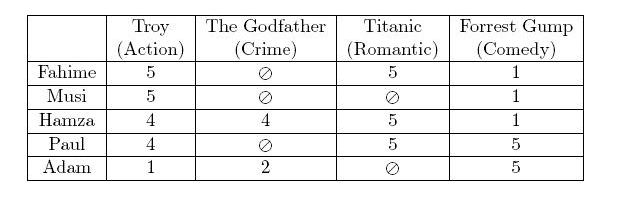
- Надо заполнить пропуски
- Предоставить рекомендацию
- Почему может не иметь смысл возвращать просто товары с максимальным рейтингом?
Введем обозначения:
- $U$ - множество пользователей
- $I$ - множество товаров
- $U_i$ - множество пользователей, оценивших товар $i$
- $I_u$ - множество товаров, оценненных пользователем $u$
- $R_{ui}$ - оценка, которую дал пользователь $u$ товару $i$
- $\hat{R}_{ui}$ - прогноз оценки
Базовое решение (baseline)¶
- $b_{ui} = \mu + b_u + b_i$,
- $b_{u} = \frac{1}{|I_u|}\sum_{i\in I_u}(R_{ui} - \mu)$
- $b_{i} = \frac{1}{|U_i|}\sum_{u\in U_i}(R_{ui} - b_u - \mu)$
Интерпретация:
- $b_u$ - насколько выше (ниже) среднего пользователь оценивает товары
- $b_i$ - насколько выше (ниже) среднего оценивается товар
Базовое решение (baseline)¶
- $b_{ui} = \mu + b_u + b_i$,
- $b_{u} = \frac{1}{|I_u|+\alpha}\sum_{i\in I_u}(R_{ui} - \mu)$
- $b_{i} = \frac{1}{|U_i|+\beta}\sum_{u\in U_i}(R_{ui} - b_u - \mu)$
Мотивация
- Сравнение с качеством более интеллектуальной модели
- Нормализация оценок (предсказываем не $R_{ui}$ а $R_{ui} - b_{ui}$)
User-based CF¶
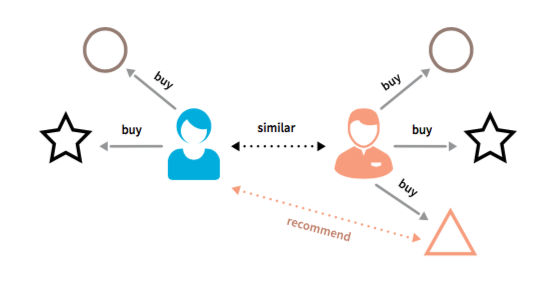
User-based CF¶
- Посчитаем сходство между пользователями $s \in \mathbb{R}^{U \times U}$
Для целевого пользователя $u$ найти похожих пользователей $N(u)$ $$ \hat{R}_{ui} = \bar{R}_u + \frac{\sum_{v \in N(u)} s_{uv}(R_{vi} - \bar{R}_v)}{\sum_{v \in N(u)} \left| s_{uv}\right|} $$
$\bar{R}_u$ - поправка на писсимизм\оптимизм пользователей
User-based CF¶
- $N(u)$ можно определять по разным соображениям:
- Брать всех
- Top-k
- $s_{uv} > \theta$
Схожесть пользователей¶
Для каждой пары $(u,v)$ надо пересечь множество оцененных товаров
Корреляция пирсона $$ s_{uv} = \frac{\sum\limits_{i \in I_u\cap I_v} (R_{ui} - \bar{R}_u)(R_{vi} - \bar{R}_v)}{\sqrt{\sum\limits_{i \in I_u\cap I_v}(R_{ui} - \bar{R}_u)^2}\sqrt{\sum\limits_{i \in I_u\cap I_v}(R_{vi} - \bar{R}_v)^2}}$$
- Корреляция Спирмана
- Косинусная мера $$ s_{uv} = \frac{\sum\limits_{i \in I_u\cap I_v} R_{ui} R_{vi}}{\sqrt{{\sum\limits_{i \in I_u\cap I_v}R_{ui}^2}}\sqrt{{\sum\limits_{i \in I_u\cap I_v}R_{vi}^2}}}$$
Item-based CF¶

Item-based CF¶
- Посчитаем сходство между товарами $s \in \mathbb{R}^{I \times I}$
- Для товара $i$ найти оцененные пользователем $u$ похожие товары: $N(i)$
Схожесть товаров¶
- Условная вероятность $$ s_{ij} = \frac{n_{ij}}{n_i} $$
- Зависимость $$ s_{ij} = \frac{n_{ij}}{n_i n_j} $$
- Какой подход работает быстрее?
- Item-based
- User-based
Контентные модели¶
Идея¶
Доселе никак не использовались признаки пользователей и товаров
- Пользователь - паттерны захода на сайт, геолокация..
- Товары - производитель, текстовое описание, категория
- Составляем для каждой пары (пользователь, товар) признаковое описание - обучаемся
- Составляем "профиль" пользователя
- Придумываем признаки для товаров
- Усредняем значения признаков для оцененных пользователем товаров
- Находим товары, наиболее близкие к предпочтениям
Модели со скрытыми факторами¶
Для каждого пользователя и товара построим векторы $p_u\in \mathbb{R}^{k}$ и $q_i \in \mathbb{R}^{k}$ так, чтобы $$ R_{ui} \approx p_u^\top q_i $$
- $p_u$ иногда получается интерпретировать как заинтересованность пользователя в некоторой категории товаров
- $q_i$ иногда получается интерпретировать как принадлежность товара к определенной категории
Кроме того, в полученном пространстве, можно считать похожесть пользователей и товаров
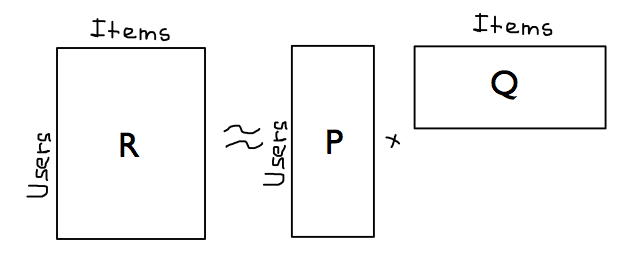
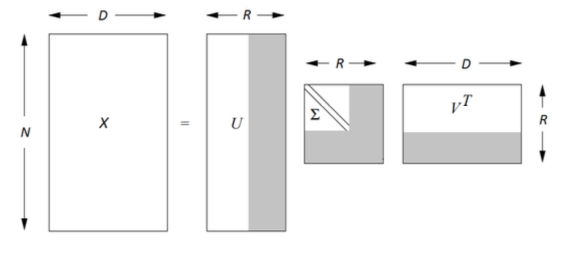
Singular Value Decomposition¶
Для любой матрицы $X$ размера $n \times d$ и ранга $r$ можно найти разложение вида: $$ X = U \Sigma V^\top ,$$ где
- $U$ - унитарная матрица, состоящая из собственных векторов $XX^\top$
- $V$ - унитарная матрица, состоящая из собственных векторов $X^\top X$
- $\Sigma$ - диагональная матрица с сингулярными числами $\sigma_i = \sqrt{\lambda_i}$
SVD разложение¶
- Надо чем-то заполнить пропуски
- Нулями
- Базовыми предсказаниями
- Как вариант
- $R' = R-B$ и заполнить $0$
- Таким образом:
- $P = U\sqrt{\Sigma}$
- $Q = \sqrt{\Sigma}V^\top$
- $\hat{R} = P^\top Q$
- А как делать предсказания для новых пользователей?
Latent Factor Model¶
- Будем оптимизировать следующий функционал $$ \sum\limits_{u,i}(R_{ui} - \bar{R}_u - \bar{R}_i - \langle p_u, q_i \rangle)^2 + \lambda \sum_u\| p_u \|^2 + \mu\sum_i\| q_i \|^2 \rightarrow \min\limits_{P, Q} $$
- С помощью градиентного спуска (на каждом шаге случайно выбирая пару $(u,i)$: $$ p_{uk} = p_{uk} + 2\alpha \left(q_{ik}(R_{ui} - \bar{R}_u - \bar{R}_i - \langle p_u, q_i \rangle) - \lambda p_{uk}\right)$$ $$ q_{ik} = q_{ik} + 2\alpha \left(p_{uk}(R_{ui} - \bar{R}_u - \bar{R}_i - \langle p_u, q_i \rangle) - \mu q_{ik}\right)$$
Оценка качества¶
- Качество рейтингов
- MAE, MSE
- Качество событий
- F-score, ROC-AUC, PR-AUC
- precision@k, recall@k
- Качество ранжирования
- $DCG@k(u) = \sum\limits_{p=1}^k \frac{rel(i,p)}{\log{(p+1)}}$
- $nDCG@k(u) = \frac{DCG@k(u)}{\max{(DCG@k(u))}}$
- Ваши идеи?
Важные факторы¶
- Холодный старт
- Возникает для новых товаров и пользователей
- Неактивные пользователи
- Масштабируемость
- Много юзеров и товаров
- Возможное низкое разнообразие
- Накручивание рейтинга