Компьютерная лингвистика (КЛ) — междисциплинарная область, которая возникла на стыке таких наук, как лингвистика, математика, информатика (Computer Science), прикладная статистика (Applied Statistics).
Несколько упрощенно задача компьютерной лингвистики может быть сформулирована как "разработка методов и средств построения лингвистических процессоров для различных прикладных задач по автоматической обработке текстов на ЕЯ (Естественном Языке)"
Приложения¶
- Машинный перевод
- Информационный поиск
- Реферирование текстов
- Классификация текстов
- Фильтрация спама
- По тональности (семантический анализ)
- По теме или жанру (multilabel classification)
- Кластеризация (категоризация) текстов
- Извлечение именованных сущностей (Named-entity recognition)
- Вопросно-ответные системы и ассистенты
- Генерация текстов
- Проверка правописания
Машинный перевод¶

NER¶

Вопросо-ответные системы и ассистенты¶

АОТ - это очень сложно¶
- Целый ряд лингвистических неоднозначностей
- Морфологические: "мой", "три", "стекло"
- Фонетические: "Надо ждать" - "Надо ж дать"
- Лексические: "кран", "ключ"
- Синтаксическая: "мужу изменять нельзя"
- Язык - динамическая система
Токенизация¶
Уровни абстракции¶
- Буквы
- Слова
- Предложения
- Параграфы
- Документы
Токенизация¶
- Токенизация - это процесс разбиения текста на элементарные состовляющие (токены)
- Токенами обычно являются слова или предложения. Для обобщения, также всключим сюда символы.
- "Кролики - это не только ценный мех, но и 3-4 килограмма диетического, легкоусвояемого мяса"
- "Через 1.5 часа поеду в Гусь-Хрустальный."
Токенизация¶
- Обычно все ограничевается использованием специальных регулярных выражений, разработанных на все случаи жизни
line = u"Через 1.5 часа поеду в Гусь-Хрустальный."
tokenizer = RegexpTokenizer('\w+| \$ [\d \.]+ | S\+')
for w in tokenizer.tokenize(line):
print(w)
line = u"Через 1.5 часа поеду в Гусь-Хрустальный."
for w in wordpunct_tokenize(line):
print(w)
Токенизация¶
- С токенизацией на предложения, как мы понимаем, тоже все неоднозначно.
- Можно так же использовать регулярные выражения
- А тожно обучиться!
- Какие бы признаки вы составили?
from nltk.tokenize import sent_tokenize
text = 'Good muffins cost $3.88 in New York. Please buy me two of them. Thanks.'
sent_tokenize(text, language='english')
text = u"Через 1.5 часа поеду в Гусь-Хрустальный. Куплю там квасу!"
for sent in sent_tokenize(text, language='english'):
print(sent)
N-граммы (n-grams)¶
- Иногда целесообразно разбивать текст не по одному слову, а по n-слов.
- Таким образом, в модели могут быть учтены словосочетания
from nltk.util import ngrams
def word_grams(words, min_=1, max_=4):
s = []
for n in range(min_, max_):
for ngram in ngrams(words, n):
s.append(u" ".join(str(i) for i in ngram))
return s
word_grams(u"I prefer cheese sause".split(u" "))
N-граммы (n-grams)¶
- n-граммы можно формировать отдельно для символов
n = 3
line = "cheese sause"
for i in range(len(line) - n + 1):
print(line[i:i+n])
Предобработка текста¶
Основные преобразования для подготовки текстов к анализу и построению моделей
- Лемматизация - придедение каждого слова в документе к его нормальной форме на основе словарей и морфологического анализа
- mystem, pymorphy
- Стемминг - отбрасывание окончаний и других изменяемых частей слов на основе набора правил
- sses → ss (caresses → caress)
- ies → i (ponies → poni)
- Удаление стоп-слов - удаление частых слов, встречающихся во всех документах. Союзы, предлоги, числительные, местоимения...
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
plurals = ['caresses', 'flies', 'dies', 'mules', 'denied',
'died', 'agreed', 'owned', 'humbled', 'sized',
'meeting', 'stating', 'siezing', 'itemization',
'sensational', 'traditional', 'reference', 'colonizer',
'plotted']
singles = [stemmer.stem(plural) for plural in plurals]
print(' '.join(singles))
from pymystem3 import Mystem
m = Mystem()
text = 'в петербурге прошел митинг против передачи исаакиевского собора рпц таксистка'
print(''.join(m.lemmatize(text)))
import pymorphy2
morph = pymorphy2.MorphAnalyzer()
res = morph.parse(u'пожарница')
for item in res:
print('====')
print(u'norm_form: {}'.format(item.normal_form))
print(u'tag: {}'.format(item.tag))
print(u'score: {}'.format(item.score))
from nltk.corpus import stopwords
stopwords = stopwords.words('russian')
print(stopwords[:20])
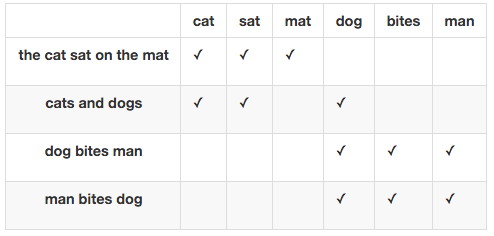
Bag of words¶
- Самый распространенный и базовый способ предствлять документы
- Каждый документ $d_i$ из корпуса документов $D$ представлен вектором $$ d_i = (w_1^i, w_2^i, \dots, w_N^i) $$
- $w_j^i$ - вес терма $j$ в документе $i$
- Порядок слов никак не учитывается
Bag of words¶
Варианты весов $w_j^i$
- Бинарный вес (есть слово или нет)
- Частота слова $j$ в документе $i$
Tf - Idf¶
- tf-idf (term frequency - inversed document frequency)
- tf(term, doc)
- Бинарные вес
- Частота слова в $j$ в документе $i$
- Сглаженная частота $\log(f_j^i + 1)$
- idf(term, corpus) = обратная частота слов в корпусе $\log\frac{D}{n_j}$
- $D$ - размер корпуса
- $n_t$ - количество документов, в которых встречается слово $j$
- tf(term, doc)

Bag of words¶
- tf-idf штрафует общие для корпуса слова
- Что делать с BoW?
- Можем находить похожие документы
- Можем использовать как признаки
- Можем сжимать в топики!
Тематические модели¶
- Тематическое моделирование - одно из современных направлений тематического анализа, активно развивающегося с конца 90-х годов.
- Идея ТМ схожа с идеей кластеризации - документы могут быть причислены к отпределенным тематикам, которые формируются на основе слов, из которых они состоят
- Хочется на выходе иметь тематическое представление каждого документа, и, желательно интерпретируемое представление каждой темы
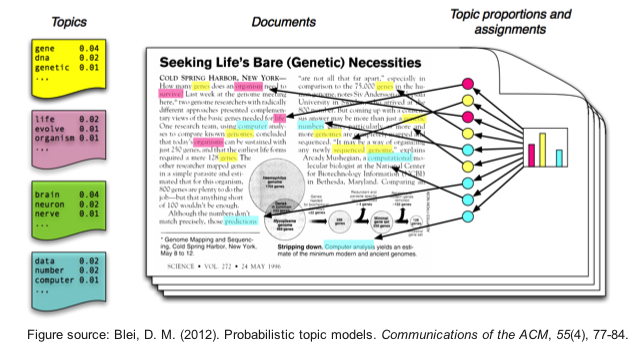

Но подробнее об этом - в следующий раз.. а сейчас..
LSA как метод понижения размерности¶
По смыслу (и технически) LSI очень поход на метод главных компонент
- Хочется перейти от избыточного представления в виде мешка слов к сжатому представлению для каждого документа (слова)
- В идеале хочется, чтобы полученные признаки-концепты были осмыслены и позволяли группировать семантически похожие документы и слова
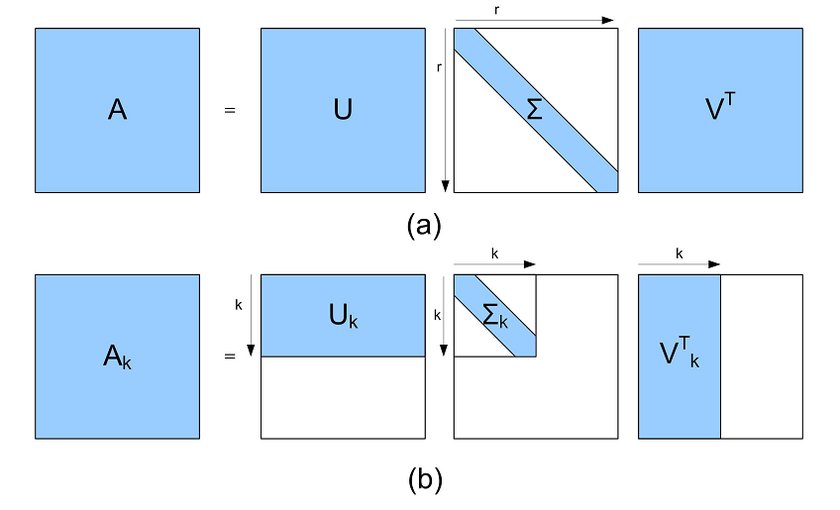
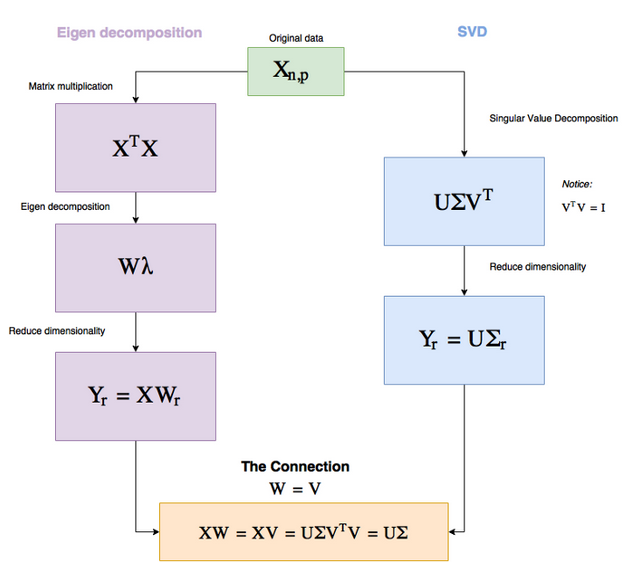
Singular Value Decomposition (SVD)¶
Сингулярное разложение¶
Для любой матрицы $A$ размера $n \times m$ и ранга $r$ можно найти разложение вида: $$ A = U \Sigma V^\top ,$$ где
- $U$ - матрица, состоящая из собственных векторов $AA^\top$
- $V$ - матрица, состоящая из собственных векторов $A^\top A$
- $\Sigma$ - диагональная матрица с сингулярными числами $s_i = \sqrt{\lambda_i}$
Для $V$ и $U$ справедливо, что $V^{-1}V = V^\top V = E$
SVD via PCA¶
Матрицы $U$ и $V$ ортогональны и могут быть использованы для перехода к ортогональному базису: $$ AV = U\Sigma $$
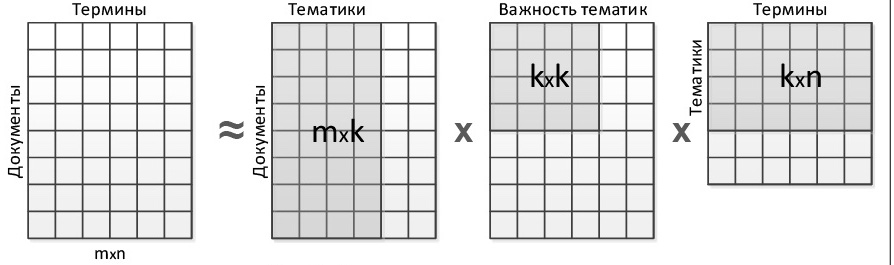
Преимущества
- Все просто
- Можно находить похожие слова через матрицу $V$ и похожие документы через матрицу $U$
- Есть практика использования LSA для задачи поиска (Latent Semantic Indexing)
- Запрос $q$, как и документы - это набор слов.
- Для того, чтобы перевести $q$ в то же самое пространство, надо сделать преобразование $$ \hat{q} = qV\Sigma^{-1} $$
Недостатки
- Плохо интерпретируется
Пример¶

Пример¶

Пример¶

