Цели и задача кластеризации¶
Задача¶
Основная задача кластерного анализа — разбиение исходного набора объектов на группы (кластеры) таким образом, чтобы:
- Объекты в группе были похожи друг на друга,
- Объекты из разных групп - отличались
Цели¶
- Поиск структуры в данных и ее интерпретация
- Поиск аномальных объектов
- Детальный анализ отдельных кластеров
Кластеризация¶
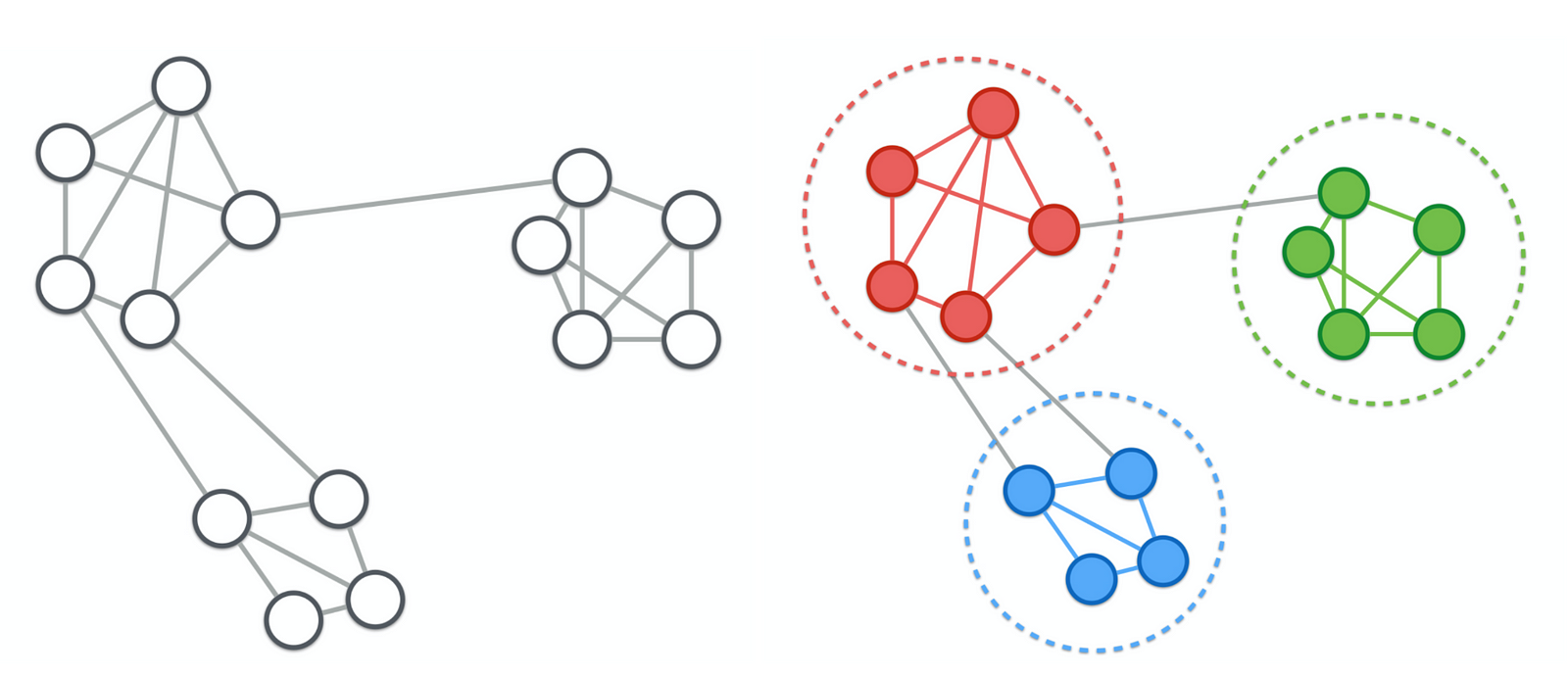
Выявление сообществ в сети*¶
Группы методов¶
- Методы основанные на прототипах
- Каждый кластер ассоциируется с виртуальрным "эталонным" объектом
- Иерархические методы
- Не простое разбиение на целая иерархия
- Плотностные методы
- Ищем плотные скопления точек в признаковом пространстве
- Вероятностные методы
- Предполагаем, что данные порождены некоторой смесью вероятностных распределений
- Спектральные методы
- Сеточные методы
Отличительные особенности методов¶
- Вычислительная сложность
- Результат в виде
- разбиения (hard clustering, partition),
- распределения (soft clustering) или
- иерархии (hierarchy)
- Форма и размер кластеров на выходе
- Устойчивость к выбросам
Метод k-средних¶
Алгоритм k-means¶
- Дано множество объектов $X = \{x_1, x_2, \dots, x_N\}$
- Кластер $C_k \Leftrightarrow \text{ центройд } \mu_k$
- Объект $x_i \in C_k \Leftrightarrow \mu_k = \arg \min\limits_{\mu_j} \|x_i - \mu_j \|^2$
- Надо найти такое разбиение на $K$ кластеров, чтобы минизировать $$ L(C) = \sum_{k=1}^K\sum_{i\in C_k} ||x_i - \mu_k||^2 \rightarrow \min\limits_C $$ $$\mu_k = \frac{1}{|C_k|} \sum _{x_n \in C_k} x_n$$

Алгоритм k-means¶
- Выбрать $K$ начальных центроидов случайным образом $\rightarrow \mu_k, \ k=1\dots K$
- Для каждой точки из датасета присвоить кластер, соответствующий ближайшему центроиду $$C_k = \{x_n : ||x_n - \mu_k||^2 \leq ||x_n - \mu_l||^2 \quad \forall l \neq k \} $$
- Обновить центройды: $$\mu_k = \frac{1}{|C_k|} \sum _{x_n \in C_k} x_n$$
- Повторять 2 и 3 до тех пор, пока изменения перестанут быть существенными
Основные факторы¶
- Начальная инициализация центройдов
- Количество кластеров
Kак выбрать K?¶
- Не пользоваться обычным k-means (X-means, ik-means)
- Посмотреть на меры качества кластеризации (об этом потом)
- Воспользоваться эвристиками
Elbow method (Метод локтя)¶
- Критерий минимизации k-means $$ L(C) = \sum_{k=1}^K\sum_{i\in C_k} ||x_i - \mu_k||^2 \rightarrow \min\limits_C $$
- Давайте возьмем всевозможные $K$, для каждого запустим алгоритм, посчитаем на результате $L(C)$ и выберем минимум!
- Ничего не выйдет... Почему?
Elbow method (Метод локтя)¶
- Выбирают такое $k$, после которого функционал $L(C)$ уменьшается не слишком быстро
- Чуть более формально: $$ D(k) = \frac{|L^{(k)}(C) - L^{(k+1)}(C)|}{|L^{(k-1)}(C) - L^{(k)}(C)|} \quad \text{"невелико"} $$
interact(elbow_demo, k=IntSlider(min=2,max=8,step=1,value=2))
Важно!¶
- Эвристика и меры качества клатеризации носят лишь рекомендательный характер!
- Если они ничего не дают, то лучше ориентироваться на свои знания в предметной области
- Или "выжать" из полученной кластеризации максимум
- 3 из 5 полученных кластеров интерпретируются - и то хорошо
Начальная инициализация центройдов¶
- Выбрать координаты $K$ случайных объектов из датасета
- Производить случайные запуски много раз и выбрать наиболее оптимальную инициализацию
- Использовать результат другой кластеризации на $K$ кластеров
- k-means++
K-means++¶
- Первый центройд выбираем случайным образом из объектов датасета
- Для каждой точки рассчитываем расстояние $d_{\min}(x_i) = \min_{\mu_j} \|x_i - \mu_j\|^2$
- Точка назначается следующим центройдом с вероятностью $p(x_i) \propto d_{\min}(x_i)$
interact(demo_kmpp, iters=IntSlider(min=1,max=6,step=1,value=1))
Резюме¶
- Метод k-средних – жадный итеративный алгоритм
- Зависит от начальных центройдов и их количества
Преимущества¶
- Прост как пробка
- Имеет множество модификаций
- Разные меры близости ($k$-medians, $k$-medoids)
- Взвешивание признаков (Weighted $k$-means)
- Нечеткая принадлежность кластеров (fuzzy $c$-means)
- Для больших данных (batch $k$-means)
- ...
- Интерпретация кластеров через центройды
Недостатки¶
- Подразумевает выпуклые кластеры
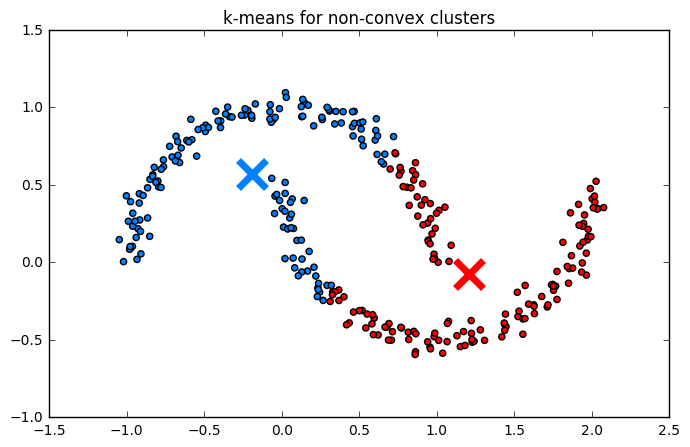
- Всегда* на выходе будет k кластеров
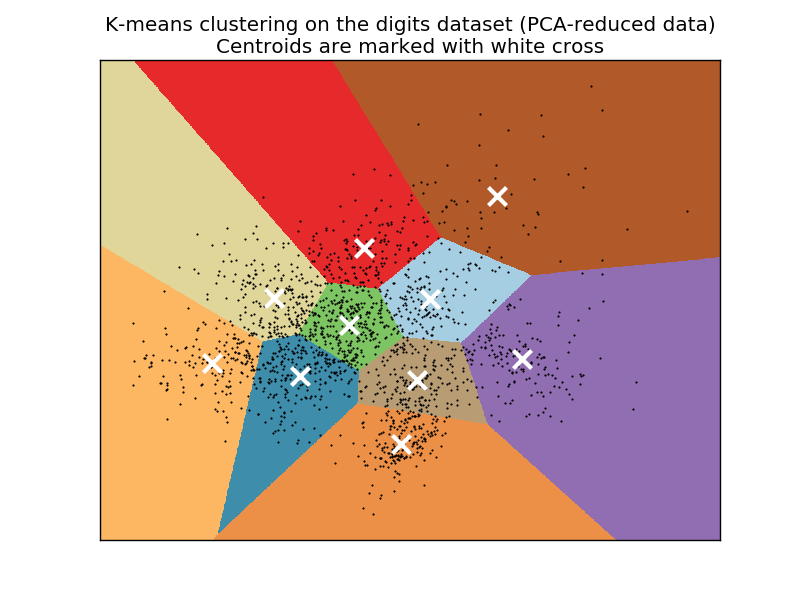
Иерархическая кластеризация¶
Мотивация¶
- Мы не всегда знаем сколько кластеров есть в данных
- Структура данных не всегда "плоская" - в ней может быть заложена иерархия!
Пример: семейства языков¶
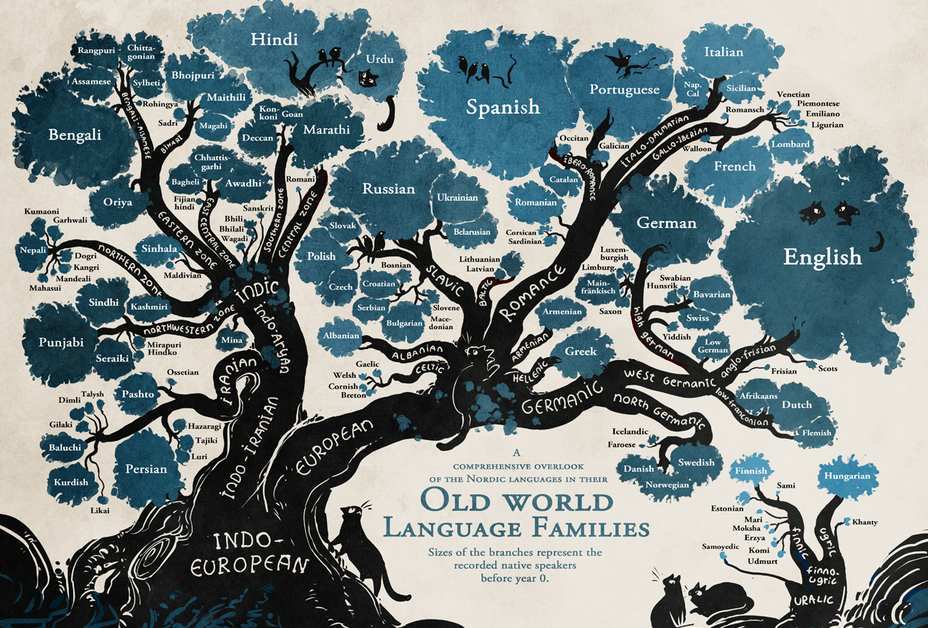
Аггломеративные алгоритмы
- начинаем с ситуации, когда каждый объект - отдельный кластер
- на каждом шаге совмещаем два наиболее близких кластера
- останавливаемся, когда получаем требуемое количество или единственный кластер
Дивизивные алгоритмы
- начинаем с ситуации, когда все объекты составляют один кластер
- на каждом шаге разделяем один из кластеров пополам
- останавливаемся, когда получаем требуемое количество или $N$ кластеров
Пример¶
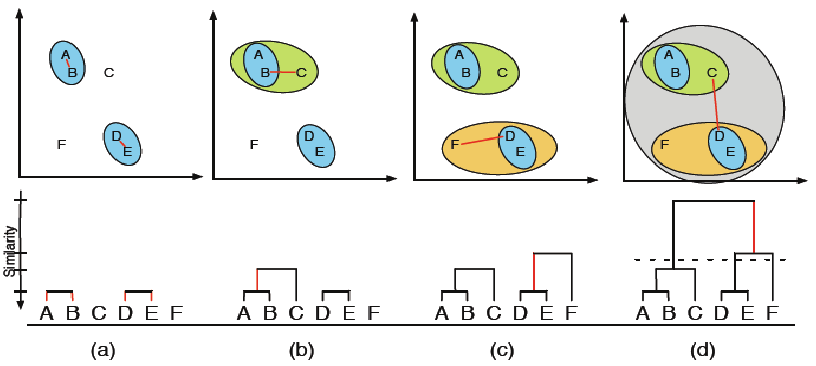
Дендрограмма¶
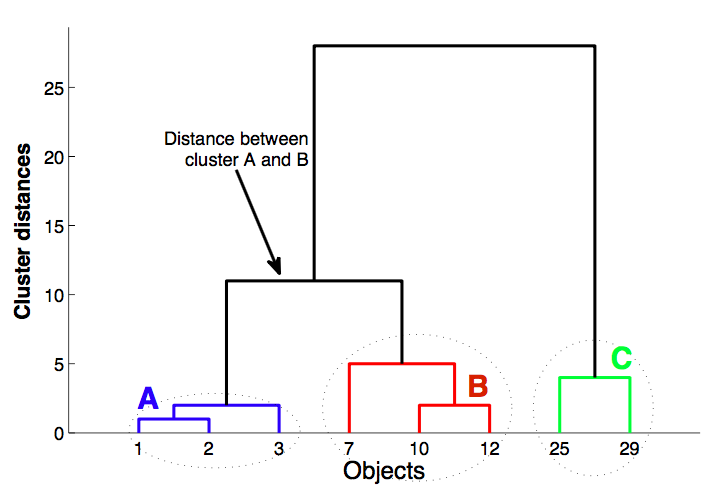
- Как определять близкие объекты?
- Как пересчитывать расстояние между кластерами после объединения?
Как определять близкие объекты? - Меры близости¶
см. лекцию про метрические методы
Пересчет расстояний после объединения кластеров¶
Single linkage $$ d_{min}(C_i, C_j) = \min_{\mathbf{x} \in C_i, \mathbf{x}' \in C_j} \|\mathbf{x} -\mathbf{x}' \| $$
Complete linkage $$ d_{max}(C_i, C_j) = \max_{\mathbf{x} \in C_i, \mathbf{x}' \in C_j} \|\mathbf{x} -\mathbf{x}' \| $$
Average linkage $$ d_{avg}(C_i, C_j) = \frac{1}{n_i n_j}\sum_{\mathbf{x} \in C_i}\sum_{\mathbf{x}' \in C_j} \|\mathbf{x} -\mathbf{x}' \| $$
Centroid linkage $$ d_{cent}(C_i, C_j) = \|\mu_i -\mu_j \| $$
Ward linkage $$ d_{ward}(C_i, C_j) = \sqrt{\frac{n_i n_j}{n_i + n_j}} \|\mu_i - \mu_j \|$$
plt.scatter(X[:,0], X[:,1])

# А теперь сделаем это с питоном
from scipy.cluster.hierarchy import dendrogram, linkage
from scipy.cluster.hierarchy import fcluster, cophenet
Z = linkage(X, method='single', metric='euclidean')
dend = dendrogram(Z)

Эвристика для оценки качества дендрограммы¶
- Кофенетическое расстояние между объектами $x_i$ и $x_j$ - высота дерева, при котором эти объекты объединились.
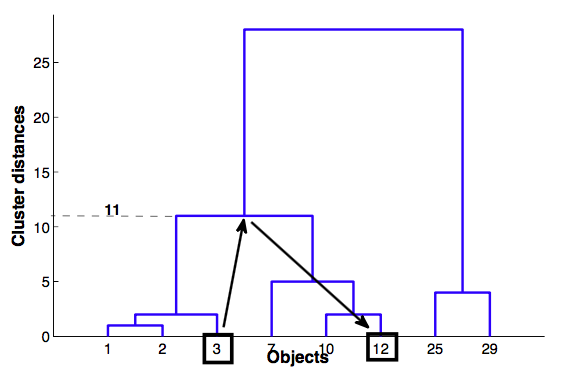
Кофенетическая корреляция¶
- Кофенетическая корреляция — коэффициент корреляции между массивами попарных расстояний и попарных кофенетических расстояний.
При "удачно" построенном дереве эти ряды должны сильно коррелировать.
interact(coph_demo, k=IntSlider(min=2, max=10, step=1, value=2),
link=['complete', 'single', 'average', 'centroid'],
metric=['euclidean', 'cityblock'])
Недостатки¶
- Требует много ресурсов
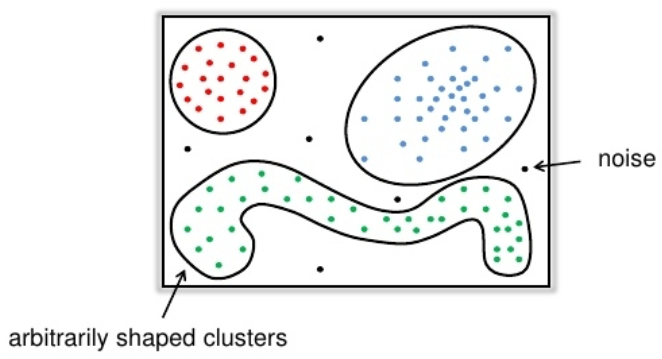
Геоданные¶
 |
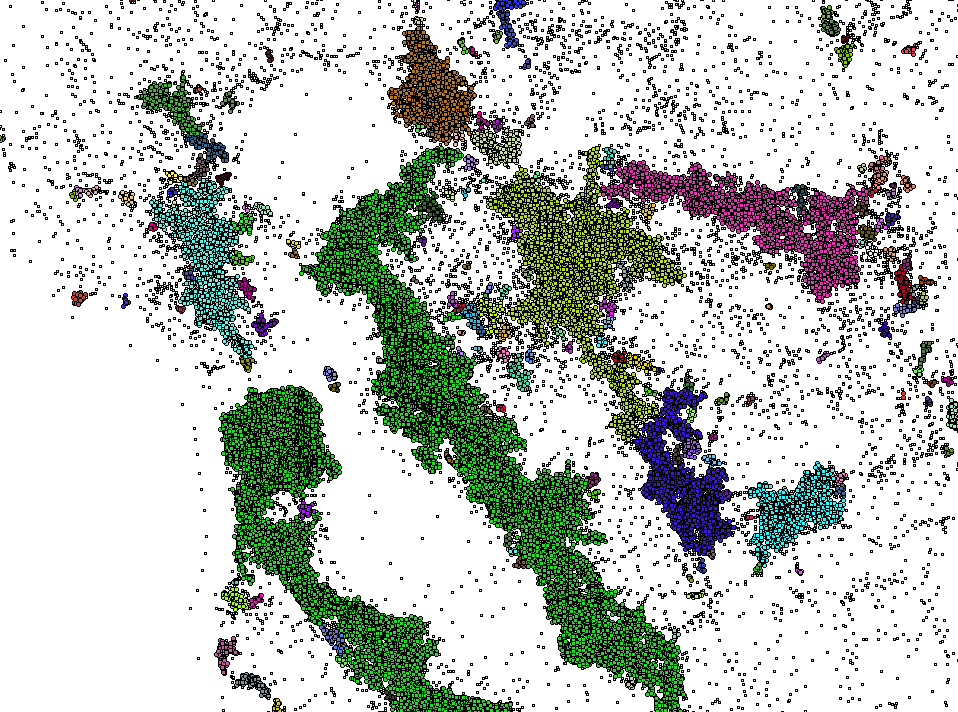 |
|---|
Основная идея¶
- Для каждой точки кластера её окрестность заданного радиуса $\epsilon$ должна содержать не менее некоторого числа точек
min_pts. - C такой точки можно начать расширение "плотного" кластера
Типы объектов¶
- Объект $x_i$ называется сore-объектом, если $N_\epsilon(x_i) \geq \texttt{min_pts}$
- Объект $x_i$ называется граничным объектом, если $N_\epsilon(x_i) < \texttt{min_pts}$, но $\exists x_j : d(x_i, x_j) \leq \epsilon$ и $x_j$ - core-объект
- Объект $x_i$ называется шумовым, если он не является ни граничным ни core объектом
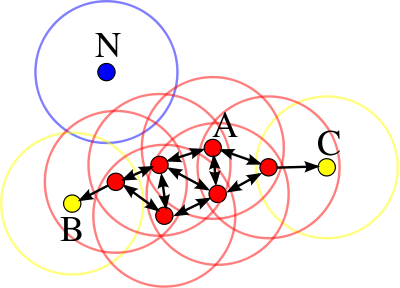
interact(dbscan_demo, eps=FloatSlider(min=0.1, max=10, step=0.05, value=1), min_pts=IntSlider(min=2, max=15, step=1, value=5))
Недостатки¶
- Не работает при различных плотностях кластеров
Cluster Validity and Quality Measures¶
Оценка качества кластеризации при известном groud truth¶
Доля правильно кластеризованных вешин¶
Пусть $\hat{\pi}$ - это полученное разбиение на кластеры, а $\pi^*$ - ground truth. Тогда доля правильно угаданных меток рассчитывается как
$$ Acc(\hat{\pi}, \pi^*) = \frac{\text{# of correctly clustered obs}}{N} \text{,}$$где объект считается правильно кластеризован, если хотя бы половина объектов из того же кластера в $\hat{\pi}$ относится к некоторому кластеру в $\pi^*$
Adjusted Rand Index¶
$$ \text{Rand}(\hat{\pi},\pi^*) = \frac{a + d}{a + b + c + d} \text{,}$$где
- $a$ - количество пар объектов, находящихся в одинаковых кластерах в $\hat{\pi}$ и $\pi^*$,
- $b$ ($c$) - количество пар объектов в одном и том же кластере в $\hat{\pi}$ ($\pi^*$), но в разных в $\pi^*$ ($\hat{\pi}$)
- $d$ - количество пар объектов в разных кластерах в $\hat{\pi}$ и $\pi^*$
Adjusted Rand Index¶
$$ \text{Rand}(\hat{\pi},\pi^*) = \frac{tp + tn}{tp + fp + fn + tn} \text{,}$$где
- $tp$ - количество пар объектов, находящихся в одинаковых кластерах в $\hat{\pi}$ и $\pi^*$,
- $fp$ ($fn$) - количество пар объектов в одном и том же кластере в $\hat{\pi}$ ($\pi^*$), но в разных в $\pi^*$ ($\hat{\pi}$)
- $tn$ - количество пар объектов в разных кластерах в $\hat{\pi}$ и $\pi^*$
Adjusted Rand Index - корректировка Rand index:
$$\text{ARI}(\hat{\pi},\pi^*) = \frac{\text{Rand}(\hat{\pi},\pi^*) - \text{Expected}}{\text{Max} - \text{Expected}}$$Так же есть Normalized Mutual Information, но результаты этой метрики схожи с ARI
Precision, Recall, F-measure¶
- $\text{Precision}(\hat{\pi},\pi^*) = \frac{tp}{tp+fn}$
- $\text{Recall}(\hat{\pi},\pi^*) = \frac{tp}{tp+fp}$
- $\text{F-measure}(\hat{\pi},\pi^*) = \frac{2\cdot Precision \cdot Recall}{Precision \cdot Recall}$
Меры валидности кластеров¶
- Измеряют полученое разбиения по отношению к качествам хорошей кластеризации
- Компактность объектов внутри кластера
- Разделимость кластеров друг от друга
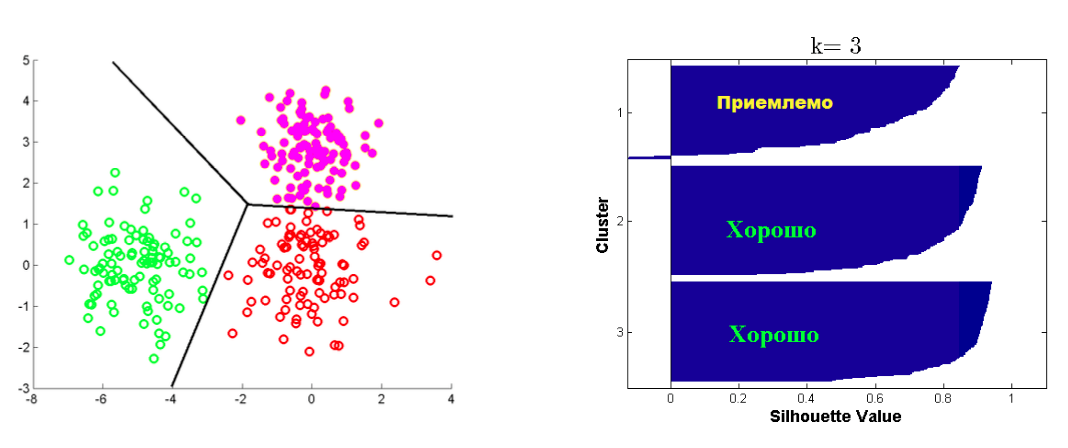
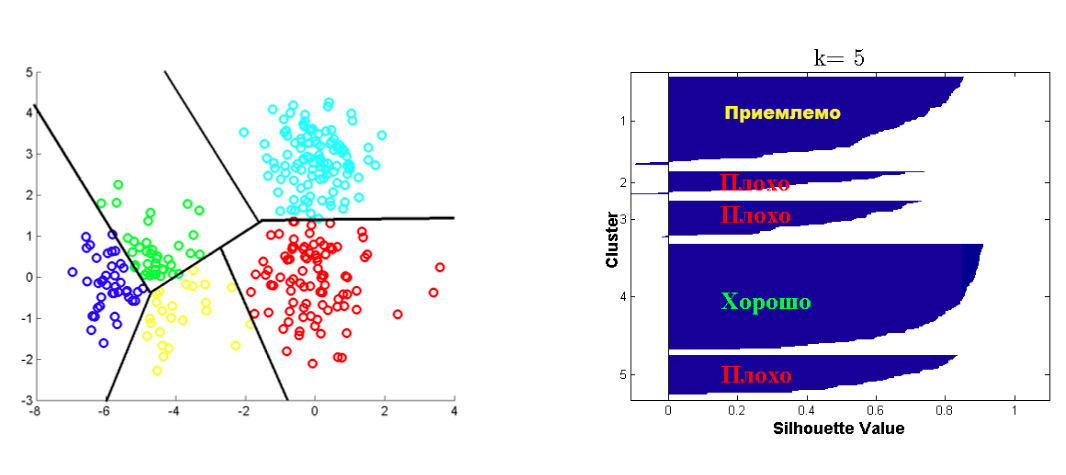
Критерий Silhouette¶
Пусть дана кластеризация в $K$ кластеров, и объект $i$ попал в $C_k$
- $a(i)$ -- среднее расстояние от $i$ объекта до объектов из $C_k$
- $b(i) = min_{j \neq k} b_j(i)$, где $b_j(i)$ -- среднее расстояние от $i$ объекта до объектов из $C_j$ $$ silhouette(i) = \frac{b(i) - a(i)}{\max(a(i), b(i))} $$ Средний silhouette для всех точек из $\mathbf{X}$ является критерием качества кластеризации.