Data Analysis
Andrey Shestakov (avshestakov@hse.ru)
Linear classification. Logistic Regression1
1. Some materials are taken from machine learning course of Victor Kitov
Let's recall previous lecture¶
- Linear regression
- linear dependence between target features and predictors
- predictors themselves can be non-linear
- Solution can be found
- analytically
- with gradient descent
- Various loss functions options
- Robust setting
- Regularization!
Linear Classification¶
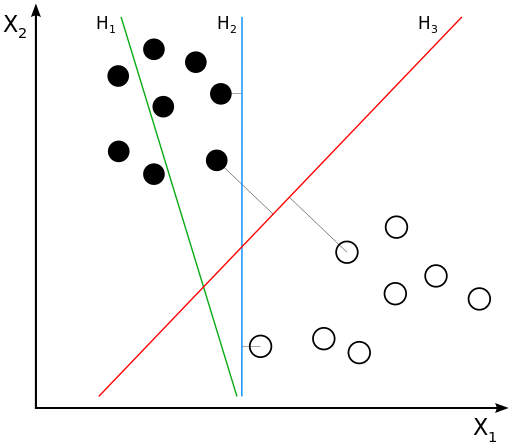
Analytical geometry reminder¶
Reminder¶
- $a=[a^{1},...a^{D}]^{T},\,b=[b^{1},...b^{D}]^{T}$
- Scalar product $\langle a,b\rangle=a^{T}b=\sum_{d=1}^{D}a_{d}b_{b}$
- $a\perp b$ means that $\langle a,b\rangle=0$
- Norm $\left\lVert a\right\rVert =\sqrt{\langle a,a\rangle}$
- Distance $\rho(a,b)=\left\lVert a-b\right\rVert =\sqrt{\langle a-b,a-b\rangle}$
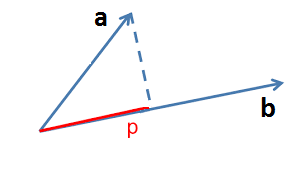
- $p=\langle a,\frac{b}{\left\lVert b\right\rVert }\rangle$
- $\left|p\right|=\left|a,\frac{b}{\left\lVert b\right\rVert }\right|$- unsigned projection length
Orthogonal vector to hyperplane¶
Theorem 1¶
Vector $w$ is orthogonal to hyperplane $w^{T}x+w_{0}=0$
Proof: Consider arbitrary $x_{A},x_{B}\in\{x:\,w^{T}x+w_{0}=0\}$: $$ \begin{align} w^{T}x_{A}+w_{0}=0 \quad \text{ (1)}\\ w^{T}x_{B}+w_{0}=0 \quad \text{ (2)} \end{align} $$ By substracting (2) from (1), obtain $w^{T}(x_{A}-x_{B})=0$, so $w$ is orthogonal to hyperplane.
Distance from point to hyperplane¶
Theorem 2¶
Distance from point $x$ to hyperplane $w^{T}x+w_{0}=0$ is equal to $\frac{w^{T}x+w_{0}}{\left\lVert w\right\rVert }$.
Proof: Project $x$ on the hyperplane, let the projection be $p$ and complement $h=x-p$, orthogonal to hyperplane. Then $$ x=p+h $$
Since $p$ lies on the hyperplane, $$ w^{T}p+w_{0}=0 $$
Since $h$ is orthogonal to hyperplane and according to theorem 1 $$ h=r\frac{w}{\left\lVert w\right\rVert },\,r\in\mathbb{R}\text{ - distance to hyperplane}. $$
Distance from point to hyperplane¶
$$ x=p+r\frac{w}{\left\lVert w\right\rVert } $$
After multiplication by $w$ and addition of $w_{0}$: $$ w^{T}x+w_{0}=w^{T}p+w_{0}+r\frac{w^{T}w}{\left\lVert w\right\rVert }=r\left\lVert w\right\rVert $$
because $w^{T}p+w_{0}=0$ and $\left\lVert w\right\rVert =\sqrt{w^{T}w}$. So we get, that $$ r=\frac{w^{T}x+w_{0}}{\left\lVert w\right\rVert } $$
Comments:
- From one side of hyperplane $r>0\Leftrightarrow w^{T}x+w_{0}>0$
- From the other side $r<0\Leftrightarrow w^{T}x+w_{0}<0$.
- Distance from hyperplane to origin 0 is $\frac{w_{0}}{\left\lVert w\right\rVert }$. So $w_{0}$ accounts for hyperplane offset.
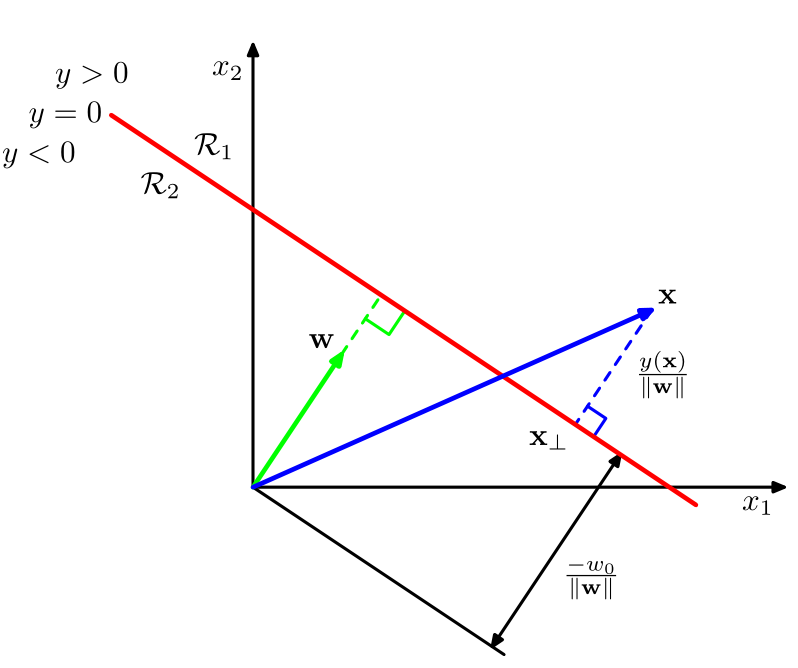
Binary linear classifier geometric interpretation¶
Binary linear classifier: $$ \widehat{y}(x)= sign\left(w^{T}x+w_{0}\right) $$
divides feature space by hyperplane $w^{T}x+w_{0}=0$.
- Confidence of decision is proportional to distance to hyperplane $\frac{\left|w^{T}x+w_{0}\right|}{\left\lVert w\right\rVert }$.
- $w^{T}x+w_{0}$ is the confidence that class is positive.
Multiclass classification with binary classifiers¶
Multiclass classification with binary classifiers¶
- Task - make $C$-class classification using many binary classifiers.
Approaches:
one-versus-all
- for each $c=1,2,...C$ train binary classifier on all objects and output $\mathbb{I}[y_{n}=c]$,
- assign class, getting the highest score in resulting $C$ classifiers.
one-versus-one
- for each $i,j\in[1,2,...C],$ $i\ne j$ learn on objects with $y_{n}\in\{i,j\}$ with output $y_{n}$
- assign class, getting the highest score in resulting $C(C-1)/2$ classifiers.
Binary linear classifier¶
- For two classes $y\in\{+1,-1\}$ classifier becomes $$ \widehat{y}(x)=\begin{cases} +1, & w_{+1}^{T}x+w_{+1,0}>w_{-1}^{T}x+w_{-1,0}\\ -1 & \text{otherwise} \end{cases} $$
- This decision rule is equivalent to $$ \begin{align*} \widehat{y}(x) & =sign(w_{+1}^{T}x+w_{+1,0}-w_{-1}^{T}x+w_{-1,0})=\\ & =sign\left(\left(w_{+1}^{T}-w_{-1}^{T}\right)x+\left(w_{+1,0}-w_{-1,0}\right)\right)\\ & =sign\left(w^{T}x+w_{0}\right) \end{align*} $$ for $w=w_{+1}-w_{-1},\,w_{0}=w_{+1,0}-w_{-1,0}$.
- Decision boundary $w^{T}x+w_{0}=0$ is linear.
- Multiclass case can be solved using multiple binary classifiers with one-vs-all, one-vs-one
- can you imagine faulty situation with those approaches for linear classifiers?
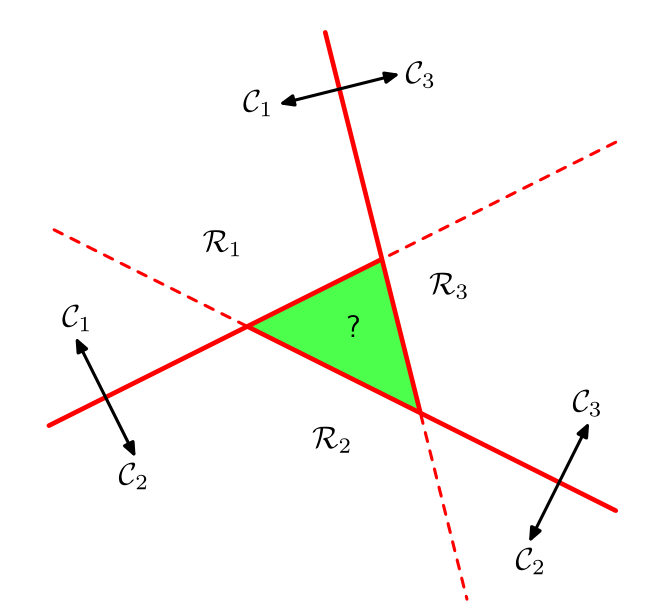
Linear classifier¶
- Classification among classes 1,2,...C.
- Use $C$ discriminant functions $g_{c}(x)=w_{c}^{T}x+w_{c0}$
- Decision rule: $$ \widehat{y}(x)=\arg\max_{c}g_{c}(x) $$
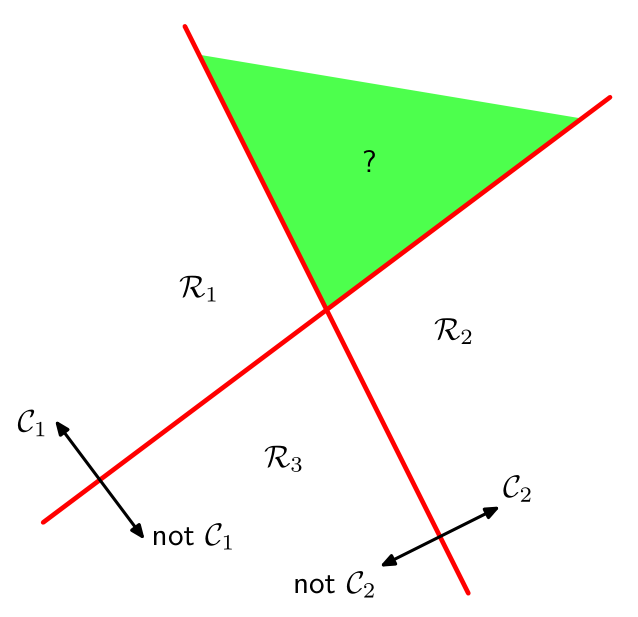
- Decision boundary between classes $y=i$ and $y=j$ is linear: $$ \left(w_{i}-w_{j}\right)^{T}x+\left(w_{i0}-w_{j0}\right)=0 $$
- Decision regions are convex
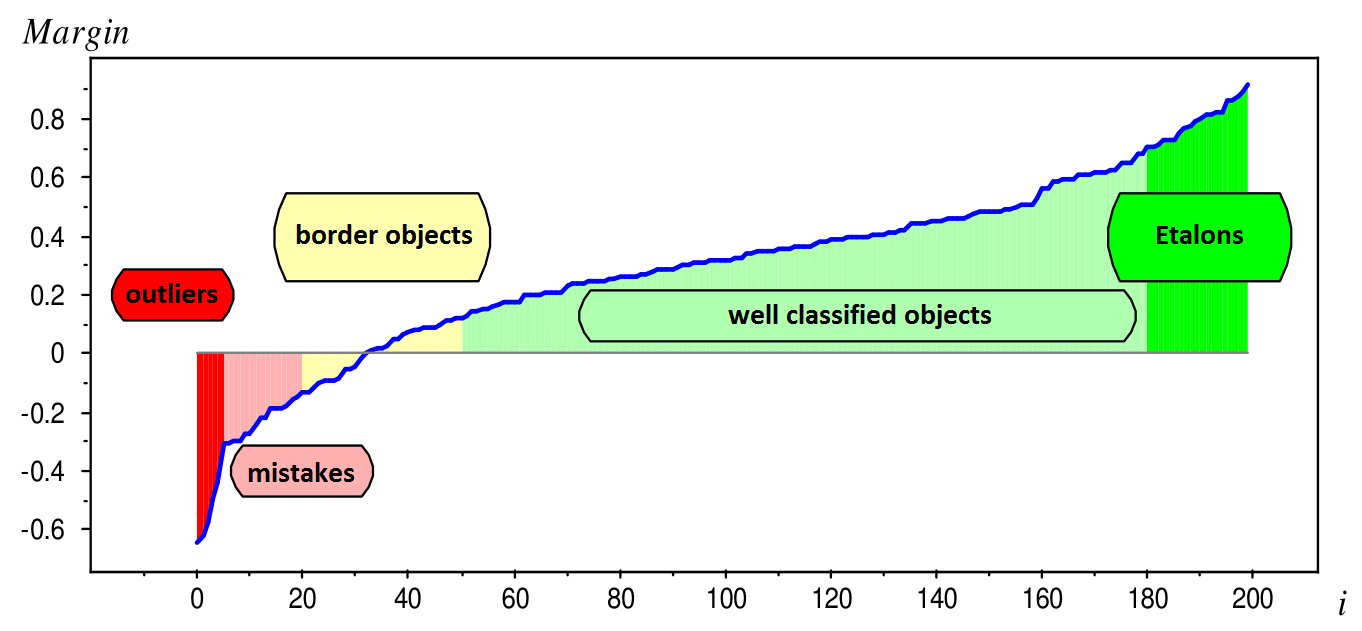
Margin of binary linear classifier¶
$$ M(x,y) =y\left(w^{T}x+w_{0}\right) $$
- Margin = score, how well classifier predicted true $y$ for object $x$.
- $M(x,y|w)>0$ <=> object $x$ is correctly classified as $y$
- signs of $w^{T}x+w_{0}$ and $y$ coincide
- $|M(x,y|w)|=\left|w^{T}x+w_{0}\right|$ - confidence of decision
- proportional to distance from $x$ to hyperplane $w^{T}x+w_{0}=0$.
Margin¶
Weights optimization¶
- Margin = score, how well classifier predicted true $y$ for object $x$.
- Task: select such $w$ to increase $M(x_{n},y_{n}|w)$ for all $n$.
- Formalization: $$ \frac{1}{N}\sum_{n=1}^{N}\mathcal{L}\left(M(x_{n},y_{n}|w)\right)\to\min_{w} $$
Misclassification rate optimization¶
- Misclassification rate optimization: $$ \frac{1}{N}\sum_{n=1}^{N}\mathbb{I}[M(x_{n},y_{n}|w)<0]\to\min_{w} $$
is not recommended:
- discontinious function, can't use numerical optimization!
continous margin is more informative than binary error indicator.\pause
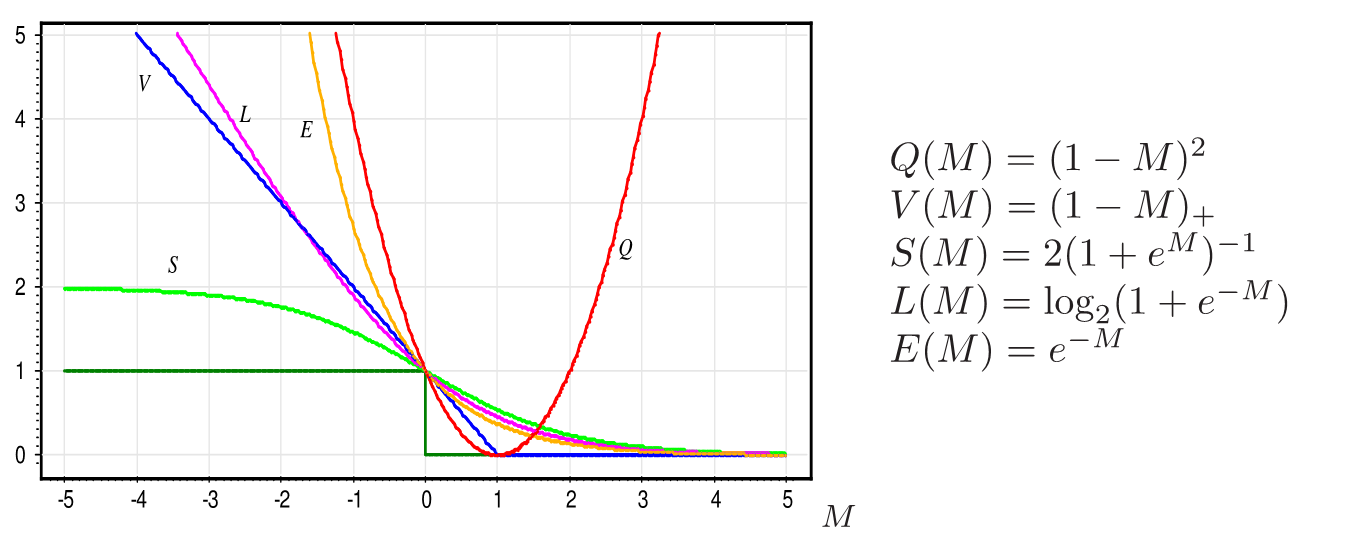
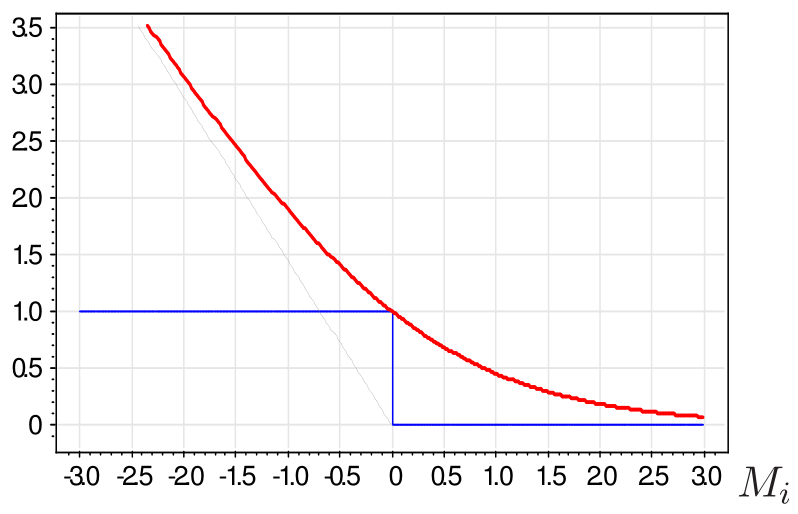
If we select loss function $\mathcal{L}(M)$ such that $\mathbb{I}[M]\le\mathcal{L}(M)$ then we can optimize upper bound on misclassification rate: $$ \begin{gathered}\begin{gathered}\text{MISCLASSIFICATION RATE}\end{gathered} =\frac{1}{N}\sum_{n=1}^{N}\mathbb{I}[M(x_{n},y_{n}|w)<0]\\ \le\frac{1}{N}\sum_{n=1}^{N}\mathcal{L}(M(x_{n},y_{n}|w))=L(w) \end{gathered} $$
Common loss functions¶
Optimization¶
Same story as in linear regression
Regularization¶
Same story as in linear regression
Regularization¶
- Insert additional requirement for regularizer $R(\beta)$ to be small: $$ \sum_{n=1}^{N}\mathcal{L}\left(M(x_{n},y_{n}|w\right)+\lambda R(\beta)\to\min_{\beta} $$
- $\lambda>0$ - hyperparameter.
- $R(\beta)$ penalizes complexity of models. $$ \begin{array}{ll} R(\beta)=||\beta||_{1} & L_{1}\text{ regularization}\\ R(\beta)=||\beta||_{2}^{2} & L_{2}\text{ regularization} \end{array} $$
$L_{1}$ regularization¶
$||w||_{1}$ regularizer should do feature selection.
Consider $$ L(w)=\sum_{n=1}^{N}\mathcal{L}\left(M(x_{n},y_{n}|w)\right)+\lambda\sum_{d=1}^{D}|w_{d}| $$
And gradient updates $$ \frac{\partial}{\partial w_{i}}L(w)=\sum_{n=1}^{N}\frac{\partial}{\partial w_{i}}\mathcal{L}\left(M(x_{n},y_{n}|w)\right)+\lambda sign (w_{i}) $$
$$ \lambda sign (w_{i})\nrightarrow0\text{ when }w_{i}\to0 $$
$L_{2}$ regularization¶
$$ L(w)=\sum_{n=1}^{N}\mathcal{L}\left(M(x_{n},y_{n}|w)\right)+\lambda\sum_{d=1}^{D}w_{d}^{2} $$
$$ \frac{\partial}{\partial w_{i}}L(w)=\sum_{n=1}^{N}\frac{\partial}{\partial w_{i}}\mathcal{L}\left(M(x_{n},y_{n}|w)\right)+2\lambda w_{i} $$ $$ 2\lambda w_{i}\to0\text{ when }w_{i}\to0 $$
- Strength of regularization $\to0$ as weights $\to0$.
- So $L_{2}$ regularization will not set weights exactly to 0.
Consider the foolowing objects
| x1 | x2 |
|---|---|
| 0 | 1 |
| 1 | 0 |
| 1 | 1 |
| 2 | 2 |
| 2 | 3 |
| 3 | 2 |
Find class prediction if $(w_0 = -0.3 , w_1 = 0.1, w_2 = 0.1)$
Logistic Regression¶
Binary classification¶
- Linear classifier: $$ score(\omega_{1}|x)=w^{T}x + w_0 = g(x) $$
- +relationship between score and class probability is assumed: $$ p(\omega_{1}|x)=\sigma(w^{T}x + w_0) $$
where $\sigma(z)=\frac{1}{1+e^{-z}}$ - sigmoid function
demo_sigmoid()

Binary classification: estimation¶
Using the property $1-\sigma(z)=\sigma(-z)$ obtain that $$ p(y=+1|x)=\sigma(w^{T}x+w_0)\Longrightarrow p(y=-1|x)=\sigma(-w^{T}x - w_0) $$
So for $y\in\{+1,-1\}$ $$ p(y|x)=\sigma(y(\langle w,x\rangle + w_0)) $$
Therefore ML estimation can be written as: $$ \prod_{i=1}^{N}\sigma( y_{i}(\langle w,x_{i}\rangle + w_0))\to\max_{w} $$
Loss function for 2-class logistic regression¶
For binary classification $p(y|x)=\sigma(y(\langle w,x\rangle + w_0))$
Estimation with ML:
$$ \prod_{i=1}^{n}\sigma(y_{i}(\langle w,x_{i}\rangle + w_0)) = \prod_{i=1}^{n}\sigma(y_{i}g(x_{i})) = \to\max_{w} $$
which is equivalent to $$ \sum_{i}^{n}\ln(1+e^{-y_{i}g(x_{i})})\to\min_{w} $$
It follows that logistic regression is linear discriminant estimated with loss function $\mathcal{L}(M)=\ln(1+e^{-M})$.
Another formulation¶
Lets present Likelihood function in another form $$ \mathcal{L}(w) = \prod_i^n p(y=+1|x)^{[y^{(i)} = +1]} p(y=-1|x)^{[y^{(i)} = -1]} \rightarrow \max_w$$ $$ -\ln{\mathcal{L}(w)} = - \sum_i^n [y^{(i)} = +1]\cdot\ln{\sigma(w^{T}x+w_0))} + {[y^{(i)} = -1]}\cdot\ln{(1-\sigma(w^{T}x+w_0))} \rightarrow \min_w$$ $$L(w) = \log{\mathcal{L}(w)} \rightarrow \min_w $$
Multiple classes¶
Multiple class classification: $$ \begin{cases} score(\omega_{1}|x)=w_{1}^{T}x + w_{0,1} \\ score(\omega_{2}|x)=w_{2}^{T}x + w_{0,2}\\ \cdots\\ score(\omega_{C}|x)=w_{C}^{T}x + + w_{0,C} \end{cases} $$
+relationship between score and class probability is assumed:
$$ p(\omega_{c}|x)=softmax(\omega_c|W, x)=\frac{exp(w_{c}^{T}x + w_{0,c})}{\sum_{i}exp(w_{i}^{T}x + w_{0,i})} $$
Estimation with ML: $$ \prod_{n=1}^{N}\prod_{c=1}^{C} softmax(\omega_c|W, x_i)^{[y_i = w_c]} $$
Which would lead us to cross-entropy
Summary¶
- Linear classifier - classifier with linear discriminant functions.
- Binary linear classifier: $\widehat{y}(x)=sign(w^{T}x+w_{0})$.
- Perceptron, logistic, SVM - linear classifiers estimated with different loss functions.
- Weights are selected to minimize total loss on margins.
- Gradient descent iteratively optimizes $L(w)$ in the direction of maximum descent.
- Stochastic gradient descent approximates $\nabla_{w}L$ by averaging gradients over small subset of objects.
- Regularization gives smooth control over model complexity.
- $L_{1}$ regularization automatically selects features.