Data Analysis
Andrey Shestakov (avshestakov@hse.ru)
Dimention Reduction. PCA. t-SNE.1
1. Some materials are taken from machine learning course of Victor Kitov
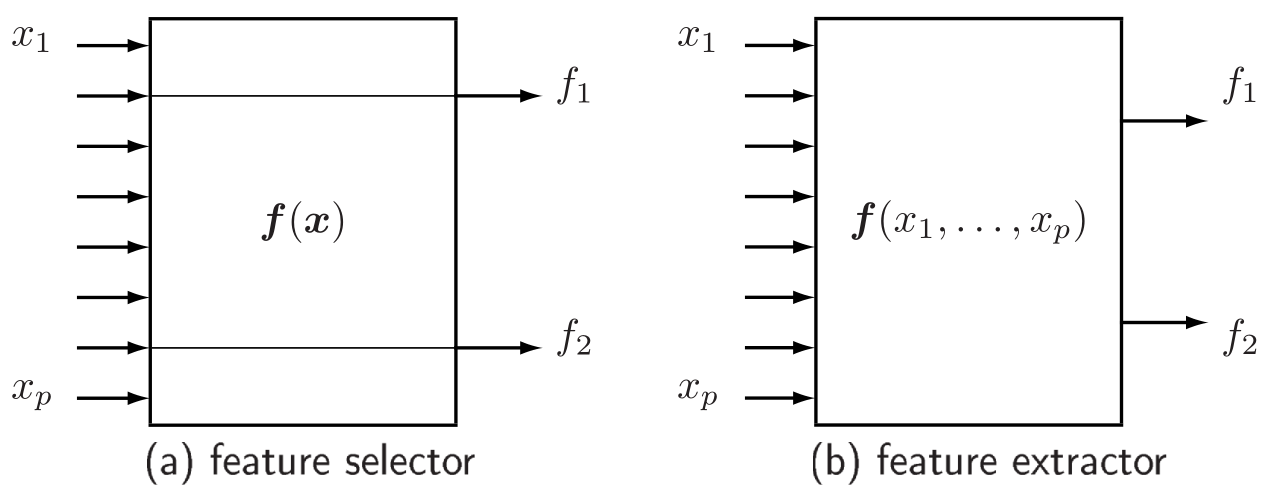
Feature Selection vs. Feature Extraction¶
Principal Component Analysis (PCA)¶
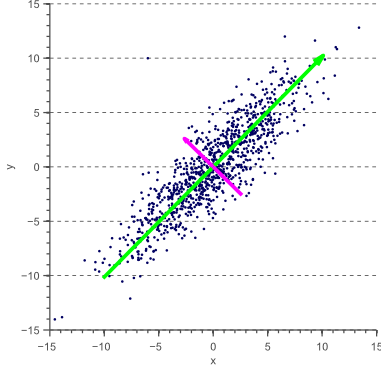
PCA¶
- Intuition 2: Find a subspace $L$ (of lesser dimention) s.t. the sum of squares of differences between points and their projections is minimized
Best hyperplane fit¶
For point $x$ and subspace $L$ denote:
- $p$: the projection of $x$ on $L$
- $h$: orthogonal complement
- $x=p+h$, $\langle p,h\rangle=0$,
Proposition¶
$\|x\|^2 = \|p\|^2 + \|h\|^2$
For training set $x_{1},x_{2},...x_{N}$ and subspace $L$ we can find:
- projections: $p_{1},p_{2},...p_{N}$
- orthogonal complements: $h_{1},h_{2},...h_{N}$.
Best subspace fit¶
Definition¶
Best-fit $k$-dimentional subspace for a set of points $x_1 \dots x_N$ is a subspace, spanned by $k$ vectors $v_1$, $v_2$, $\dots$, $v_k$, solving
$$ \sum_{n=1}^N \| h_n \| ^2 \rightarrow \min\limits_{v_1, v_2,\dots,v_k}$$
or
$$ \sum_{n=1}^N \| p_n \| ^2 \rightarrow \max\limits_{v_1, v_2,\dots,v_k}$$
Definition of PCA¶
Principal components $a_1, a_2, \dots, a_k$ are vectors, forming orthonormal basis in the k-dimentional subspace of best fit
Properties¶
- Not invariant to translation:
- center data before PCA: $$ x\leftarrow x-\mu\text{ where }\mu=\frac{1}{N}\sum_{n=1}^{N}x_{n} $$
- Not invariant to scaling:
- scale features to have unit variance before PCA
Example: line of best fit¶
- In PCA the sum of squared perpendicular distances to line is minimized:
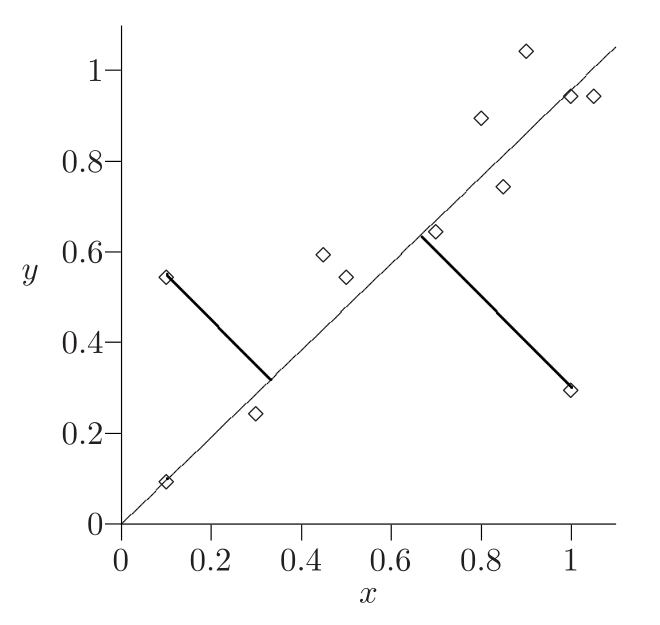
- What is the difference with least squares minimization in regression?
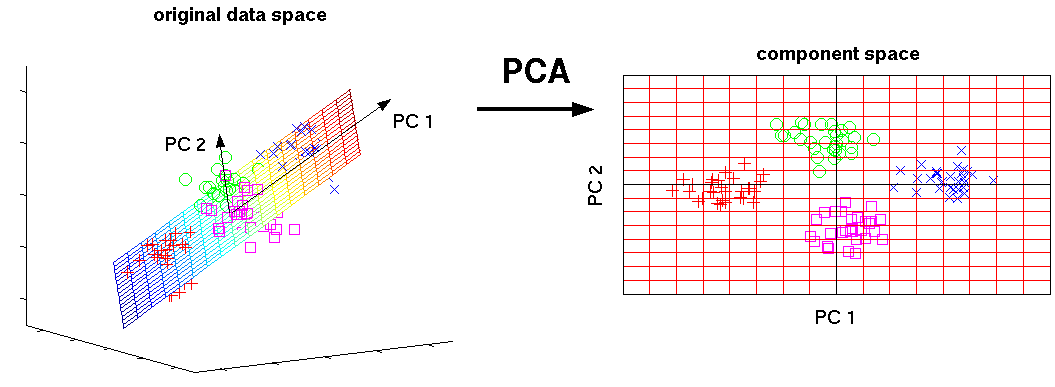
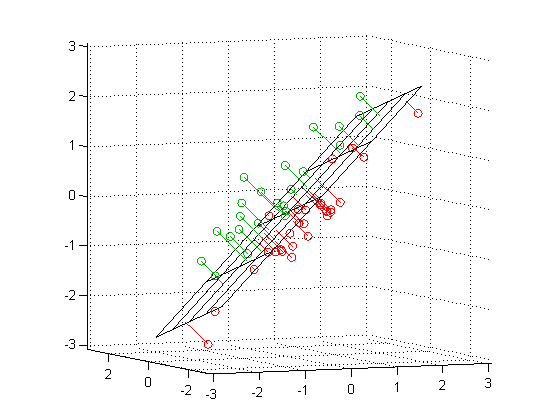
Example: plane of best fit¶

EigenFaces¶
Eigenvectors are called eigenfaces. Projections on first several eigenfaces describe most of face variability.

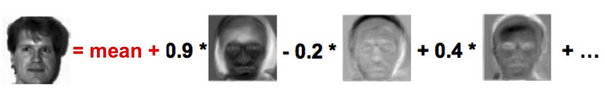
Quality of approximation¶
Quality of approximation¶
Consider vector $x$. Since all $D$ principal components form a full othonormal basis, $x$ can be written as $$ x=\langle x,a_{1}\rangle a_{1}+\langle x,a_{2}\rangle a_{2}+...+\langle x,a_{D}\rangle a_{D} $$
Let $p^{K}$ be the projection of $x$ onto subspace spanned by first $K$ principal components: $$ p^{K}=\langle x,a_{1}\rangle a_{1}+\langle x,a_{2}\rangle a_{2}+...+\langle x,a_{K}\rangle a_{K} $$
Error of this approximation is $$ h^{K}=x-p^{K}=\langle x,a_{K+1}\rangle a_{K+1}+...+\langle x,a_{D}\rangle a_{D} $$
Quality of approximation¶
Using that $a_{1},...a_{D}$ is an orthonormal set of vectors, we get
$$ \begin{gathered}\left\lVert x\right\rVert ^{2}=\langle x,x\rangle=\langle x,a_{1}\rangle^{2}+...+\langle x,a_{D}\rangle^{2}\\ \left\lVert p^{K}\right\rVert ^{2}=\langle p^{K},p^{K}\rangle=\langle x,a_{1}\rangle^{2}+...+\langle x,a_{K}\rangle^{2}\\ \left\lVert h^{K}\right\rVert ^{2}=\langle h^{K},h^{K}\rangle=\langle x,a_{K+1}\rangle^{2}+...+\langle x,a_{D}\rangle^{2} \end{gathered} $$
We can measure how well first $K$ components describe our dataset $x_{1},x_{2},...x_{N}$ using relative loss $$ \begin{equation} L(K)=\frac{\sum_{n=1}^{N}\left\lVert h_{n}^{K}\right\rVert ^{2}}{\sum_{n=1}^{N}\left\lVert x_{n}\right\rVert ^{2}}\label{eq:relative approximation error} \end{equation} $$ or relative score $$ \begin{equation} S(K)=\frac{\sum_{n=1}^{N}\left\lVert p_{n}^{K}\right\rVert ^{2}}{\sum_{n=1}^{N}\left\lVert x_{n}\right\rVert ^{2}}\label{eq:relative approximation quality} \end{equation} $$ Evidently $L(K)+S(K)=1$.
Contribution of individual component¶
Contribution of $a_{k}$ for explaining $x$ is $\langle x,a_{k}\rangle^{2}$.
Contribution of $a_{k}$ for explaining $x_{1},x_{2},...x_{N}$ is: $$ \sum_{n=1}^{N}\langle x_{n},a_{k}\rangle^{2} $$
Explained variance ratio: $$ E(a_{k})=\frac{\sum_{n=1}^{N}\langle x_{n},a_{k}\rangle^{2}}{\sum_{d=1}^{D}\sum_{n=1}^{N}\langle x_{n},a_{d}\rangle^{2}}=\frac{\sum_{n=1}^{N}\langle x_{n},a_{k}\rangle^{2}}{\sum_{n=1}^{N}\left\lVert x_{n}\right\rVert ^{2}} $$
- Explained variance ratio measures relative contribution of component $a_{k}$ to explaining our dataset $x_{1},...x_{N}$.
- Note that $\sum_{k=1}^{K}E(a_{k})=S(K)$.
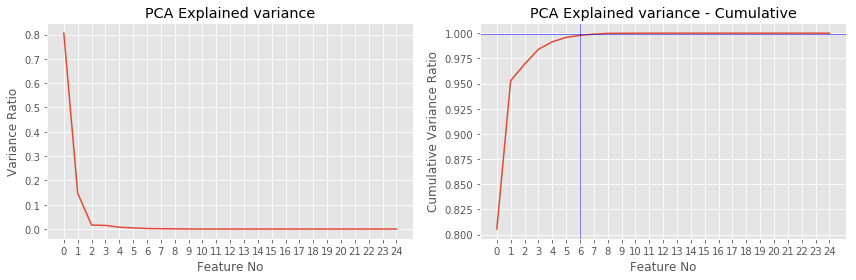
How many principal components?¶
- Take most significant components until their variance falls sharply down
- Or take minimum $K$ s.t. $L(K) \leq t$ or $S(K) \geq 1-t$
Construction of PCA¶
Construction of PCA¶
- Datapoints in $X$ assumed to be centralized and scaled (!)
- Principal components $a_{1},a_{2},...a_{D}\in\mathbb{R}^{D}$ are found such that $\langle a_{i},a_{j}\rangle=\begin{cases} 1, & i=j\\ 0 & i\ne j \end{cases}$
- $Xa_{i}$ is a vector of projections of all objects onto the $i$-th principal component.
- For any object $x$ its projections onto principal components are equal to: $$ p=A^{T}x=[\langle a_{1},x\rangle,...\langle a_{D},x\rangle]^{T} $$ where $A=[a_{1};a_{2};...a_{D}]\in\mathbb{R}^{DxD}$.
Construction of PCA¶
- $a_{1}$ is selected to maximize $\left\lVert Xa_{1}\right\rVert $ subject to $\langle a_{1},a_{1}\rangle=1$
- $a_{2}$ is selected to maximize $\left\lVert Xa_{2}\right\rVert $ subject to $\langle a_{2},a_{2}\rangle=1$, $\langle a_{2},a_{1}\rangle=0$
- $a_{3}$ is selected to maximize $\left\lVert Xa_{3}\right\rVert $ subject to $\langle a_{3},a_{3}\rangle=1$, $\langle a_{3},a_{1}\rangle=\langle a_{3},a_{2}\rangle=0$
etc.
Derivation of 1st component¶
$$ \begin{equation} \begin{cases} \|X a_1 \|^2 \rightarrow \max_{a_1} \\ a_1^\top a_1 = 1 \end{cases} \end{equation} $$
- Lagrangian of optimization problem $$ \mathcal{L}(a_1, \nu) = a_1^\top X^\top X a_1 - \nu (a_1^\top a_1 - 1) \rightarrow max_{a_1, \nu}$$
- Derivative w.r.t. $a_1$ $$ \frac{\partial\mathcal{L}}{\partial a_1} = 2X^\top X a_1 - 2\nu a_1 = 0 $$
- so $a_1$ is selected from a set of eigenvectors of $X^\top X$. But which one?
Useful properties of $X^\top X$¶
- $X^\top X$ - symmetric and positive semi-definite
- $(X^\top X)\top = X^\top X$
- $\forall a \in \mathbb{R}^D:\ a^\top (X^\top X) a = \|Xa\|^2 \geq 0$
- Properties
- All eigenvalues $\lambda_i \in \mathbb{R}, \lambda_i \geq 0$ (we also assume $\lambda_1 \geq \lambda_2 \geq \dots \geq \lambda_d $)
- Eigenvectors for $\lambda_i \neq \lambda_j $ are orthogonal: $v_i^\top v_j = 0$
- For each unique eigenvalue $\lambda_i$ there is a unique $v_i$
Back to component 1¶
Initially, our objective was $$\|X a_1 \|^2 = a_1^\top X^\top X a_1 \rightarrow \max_{a_1}$$
From lagrangian we derived that $$X^\top X a_1 = \nu a_1$$
Putting one in to another: $$ a_1^\top X^\top X a_1 = \nu a_1^\top a_1 = \nu \rightarrow \max$$
That means:
- $\nu$ should be the greatest eigenvalue of matrix $X^\top X$, which is - $\lambda_1$
- $a_1$ is eigenvector, correspondent to $\lambda_1$
Derivation of 2nd component¶
$$ \begin{equation} \begin{cases} \|X a_2 \|^2 \rightarrow \max_{a_2} \\ a_2^\top a_2 = 1 \\ a_2^\top a_1 = 0 \end{cases} \end{equation} $$
- Lagrangian of optimization problem $$ \mathcal{L}(a_2, \nu,\alpha) = a_2^\top X^\top X a_2 - \nu (a_2^\top a_2 - 1) - \alpha (a_1^\top a_2) \rightarrow max_{a_2, \nu,\alpha}$$
- Derivative w.r.t. $a_2$ $$ \frac{\partial\mathcal{L}}{\partial a_2} = 2X^\top X a_2 - 2\nu a_2 - \alpha a_1 = 0 $$
Derivation of 2nd component¶
By multiplying by $a_1^\top$ : $$ a_1^\top\frac{\partial\mathcal{L}}{\partial a_2} = 2a_1^\top X^\top X a_2 - 2\nu a_1^\top a_2 - \alpha a_1^\top a_1 = 0 $$
It follows that $\alpha a_1^\top a_1 = \alpha = 0$, which means that $$ \frac{\partial\mathcal{L}}{\partial a_2} = 2X^\top X a_2 - \nu a_2 = 0 $$ And $a_2$ is selected from a set of eigenvectors of $X^\top X$. Again, which one?
Derivations of other components proceeds in the same manner
PCA solution¶
- Center $x_{1},...x_{N}$ to have zero mean.
- Scale $x_{1},...x_{N}$ to have equal variance.
- Form $X=[x_{1}^{T};...x_{N}^{T}]^{T}\in\mathbb{R}^{NxD}$
- Estimate sample covariance matrix of x: $\widehat{\Sigma}=\frac{1}{N}X^{T}X$
- Find eigenvalues $\lambda_{1}\ge\lambda_{2}\ge...\ge\lambda_{D}\ge0$ and corresponding eignevectors $a_{1},a_{2},...a_{D}$.
- $a_{1},a_{2},...a_{k}$ are first $k$ principal components, $k=1,2,...D$.
- Sum of squared projections onto $a_{i}$ is $\left\lVert Xa_{i}\right\rVert ^{2}=\lambda_{i}$.
- Explained variance ratio by component $a_{i}$ is equal to $$ \frac{\lambda_{i}}{\sum_{d=1}^{D}\lambda_{d}} $$
PCA summary¶
- Dimensionality reduction - common preprocessing step for efficiency and numerical stability.
- Subspace of best fit of rank $k$ for training set $x_{1},...x_{N}$ is k-dimensional subspace $L(v_{1},...v_{k})$, minimizing:
$$ \left\lVert h_{1}\right\rVert ^{2}+...+\left\lVert h_{N}\right\rVert ^{2}\to\min_{v_{1},...v_{k}} $$
- Solution vectors are called top $k$ principal components.
- Principal component analysis - expression of $x$ in terms of first $k$ principal components.
- It is unsupervised linear dimensionality reduction.
- Solution is achieved on top $k$ eigenvectors $a_{1},...a_{k}$.
- PCA tutorial
Multidimentional scaling - intuinition¶
Find feature space with lesser dimentions s.t. distances in initial space are conserved in the new one. A bit more formally:
- Given $X = [x_1,\dots, x_n]\in \mathbb{R}^{N \times D}$ and/or $\delta_{ij}$ - proximity measure between $(x_i,x_j)$ in initial feature space.
- Find $Y = [y_1,\dots,y_n] \in \mathbb{R}^{N \times d}$ such that $\delta_{ij} \approx d(y_i, y_j) = \|y_i-y_j\|^2$
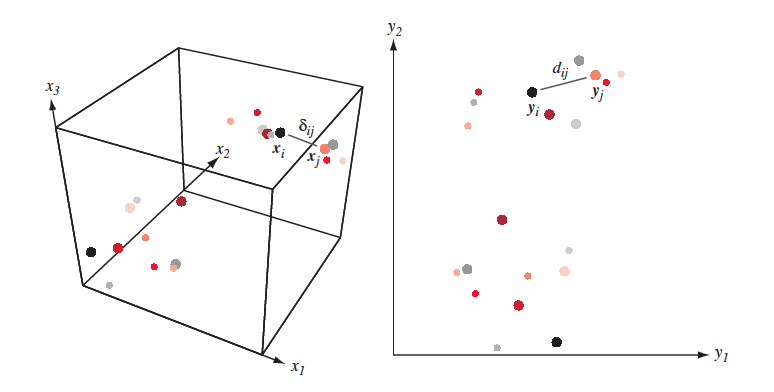
Multidimentional scaling¶
It is clear, that most of the times distances won't be conserved completely:
Multidimentional scaling approaches¶
- classical MDS (essentially PCA)
- metric MDS
- non-metric MDS
- But what if we want to conserve not the distances themselves, but the structure of inital dataset? Like neighbourhood of each point?
- Here comes t-SNE !!!
T-SNE¶
- t-SNE - is not multidimentional scaling, but the goal is somewhat similar
- There are going to be 3 types of similarities:
- Similarity between points in initial feature space
- Similarity between points in derived feature space
- Similarity between feature spaces!
T-SNE¶
- Similarity between points in initial feature space $\mathbb{R}^D$ $$ p(i, j) = \frac{p(i | j) + p(j | i)}{2N}, \quad p(j | i) = \frac{\exp(-\|\mathbf{x}_j-\mathbf{x}_i\|^2/{2 \sigma_i^2})}{\sum_{k \neq i}\exp(-\|\mathbf{x}_k-\mathbf{x}_i\|^2/{2 \sigma_i^2})} $$ $\sigma_i$ is set by user (implicitly)
- Similarity between points in derived feature space $\mathbb{R}^d, d << D$ $$ q(i, j) = \frac{g(|\mathbf{y}_i - \mathbf{y}_j|)}{\sum_{k \neq l} g(|\mathbf{y}_i - \mathbf{y}_j|)} $$ where $g(z) = \frac{1}{1 + z^2}$ - is student t-distribution with dof=$1$
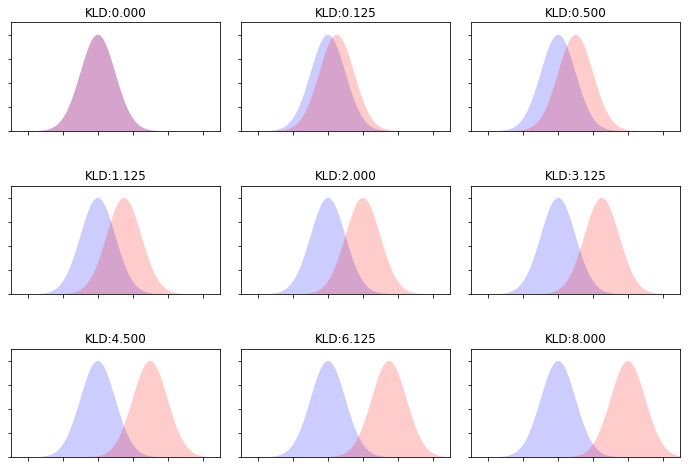
- Similarity between feature spaces (Kullback–Leibler divergence) $$ J_{t-SNE}(y) = KL(P \| Q) = \sum_i \sum_j p(i, j) \log \frac{p(i, j)}{q(i, j)} \rightarrow \min\limits_{\mathbf{y}} $$
Optimization¶
- Optimize $J_{t-SNE}(y)$ with SGD
$$\frac{\partial J_{t-SNE}}{\partial y_i}=4 \sum_j(p(i,j)−q(i,j))(y_i−y_j)g(|y_i−y_j|)$$
- Article
- Examples
- Demo and advises
- t-SNE is unstable
- Size of clusters means anything
- Distance means anything
- Random data can provide structure
