Data Analysis
Andrey Shestakov (avshestakov@hse.ru)
Introduction to Natural Language Processing1
1. Some materials are taken from machine learning course of Victor Kitov
Huge amount of information is represented in a form of natual language:
- Blog-posts
- Comments
- Review
- Search queries
- Code
- ...
Need a way to process this information:
- transfer "characters" to vectors
- recognize key entities in text
- understand relationships between them
- ...
Computational linguistics — is an interdisciplinary field concerned with the statistical or rule-based modeling of natural language from a computational perspective.
Applications¶
- Machine Translation
- Information retrieval
- Text summarization
- Text Classification
- Spam filtering
- Semantic analysis
- Multilabel classification
- Text Categorization
- Named-entity recognition
- QA-systems and assistants
- Text Generation
- Spell-checking and next-word suggestion
Machine Translation¶

Named Entity Recognition¶

QA-systems and assistants¶

Text suggestion¶
NLP is HARD!¶
- Various linguistic uncertainties
- morphologic: "мой", "три", "стекло"
- phonetic: "Надо ждать" - "Надо ж дать"
- lexical: "кран", "ключ"
- syntactical: "мужу изменять нельзя"
- Language is in dynamic!
Tokenization¶
Levels of abstraction¶
- Characters
- Words
- Sentences
- Paragraphs
- Documents
Tokenization¶
- Tokenization - task of document decomposition on to tokens (elemental units)
- Usually, word-based granularity is considered
- "Кролики - это не только ценный мех, но и 3-4 килограмма диетического, легкоусвояемого мяса"
- "Через 1.5 часа поеду в Гусь-Хрустальный."
Tokenization of words¶
- Special regular expressions can be utilized to word this out
In [ ]:
line = u"Через 1.5 часа поеду в Гусь-Хрустальный."
for w in line.split(' '):
print(w)
In [ ]:
line = u"Через 1.5 часа поеду в Гусь-Хрустальный."
tokenizer = RegexpTokenizer('\w+| \$ [\d \.]+ | S\+')
for w in tokenizer.tokenize(line):
print(w)
In [ ]:
line = u"Через 1.5 часа поеду в Гусь-Хрустальный."
for w in wordpunct_tokenize(line):
print(w)
In [ ]:
line = u'テキストで表示ロシア語'
line = u'Nach der Wahrscheinlichkeitstheorie steckt alles in Schwierigkeiten!'
# =(
Tokenization of sentences¶
- Also not clear
- May use regex
- Or some model)
In [ ]:
from nltk.tokenize import sent_tokenize
text = 'Good muffins cost $3.88 in New York. Please buy me two of them. Thanks.'
sent_tokenize(text, language='english')
In [ ]:
text = u"Через 1.5 часа поеду в Гусь-Хрустальный. Куплю там квасу!"
for sent in sent_tokenize(text, language='english'):
print(sent)
n-grams¶
- Sometimes it is usefull to consider sequences of tokens
- To catch context
- To be robust to spelling errors
In [ ]:
from nltk.util import ngrams
def word_grams(words, min_=1, max_=4):
s = []
for n in range(min_, max_):
for ngram in ngrams(words, n):
s.append(u" ".join(str(i) for i in ngram))
return s
word_grams(u"I prefer cheese sause".split(u" "))
In [ ]:
n = 3
line = "cheese sause"
for i in range(len(line) - n + 1):
print(line[i:i+n])
Byte-pair encoding¶
- Prepare a large enough training data (i.e. corpus)
- Define a desired subword vocabulary size
- Split words to sequence of characters
- Produce new subword as concatination of most frequent pair of characters
- Recalculate frequences and repeat "4" until desired vocalularly size is met
I saw a girl with a telescope. ->
['▁I', '▁saw', '▁a', '▁girl', '▁with', '▁a', '▁', 'te', 'le', 's', 'c', 'o', 'pe', ‘.’]
Text normalization¶
Two types of text normalization
- Lemmatization - process of transformation of a word to its base form (normal form) based on dictionaries morphological analysis
- mystem, pymorphy
- Stemming - rule-based process of reduction of a words to its stem based
- sses → ss (caresses → caress)
- ies → i (ponies → poni)
In [ ]:
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
plurals = ['caresses', 'flies', 'dies', 'mules', 'denied',
'died', 'agreed', 'owned', 'humbled', 'sized',
'meeting', 'stating', 'siezing', 'itemization',
'sensational', 'traditional', 'reference', 'colonizer',
'plotted']
singles = [stemmer.stem(plural) for plural in plurals]
print(' '.join(singles))
In [ ]:
from pymystem3 import Mystem
m = Mystem()
text = 'в петербурге прошел митинг против передачи исаакиевского собора рпц'
print(''.join(m.lemmatize(text)))
In [ ]:
import pymorphy2
morph = pymorphy2.MorphAnalyzer()
res = morph.parse(u'пожарница')
for item in res:
print('====')
print(u'norm_form: {}'.format(item.normal_form))
print(u'tag: {}'.format(item.tag))
print(u'score: {}'.format(item.score))
Other preprocessing techniques¶
- high-frequency word (stop-words) removal
- Unions, prepositions, numerals, pronouns
- low-frequency word removal
In [ ]:
from nltk.corpus import stopwords
stopwords = stopwords.words('russian')
print(stopwords[:20])
Other preprocessing techniques¶
- Switching to lowercase
- may loose meaning (US > us) or emotion (GREAT > great)
Bag of words¶
- Most common way to represent documents
- Each document $d_i$ from corpus $D$ is represented with vector $$ d_i = (w_1^i, w_2^i, \dots, w_N^i) $$
- $w_j^i$ - weight of word $j$ in document $i$
- word order is ignored

Bag of words¶
$w_j^i$ can be calculated as
- Binary signal (does document contain the word)
- Frequency of word $j$ in document $i$
Tf - Idf¶
- tf-idf (term frequency - inversed document frequency)
- tf(term, doc)
- Binary signal
- Frequency of word $j$ in document $i$
- Smoothed frequency $\log(f_j^i + 1)$
- idf(term, corpus) = inversed document frequency if a word $j$ in corpus $D$: $\log\left(\frac{|D|}{n_j} + 1\right)$
- $|D|$ - size of corpus
- $n_t$ - number of documents which contain word $j$
- idf measures how specifit a word is
- tf(term, doc)
Bag of words¶
- Additionaly, l1 or l2 normalization is applied to document vectors
- Normalization is usually good for models
- Maintain "meaning" of a document (for longer documents words' frequency are usually greater)
- Ok, what we can do now with BoW?
- Put it as features in models (linear models, naive bayes)
- Use it to find similar documents (with cosine or jaccard distance)
- Compress it to "topics"!
LSA and feature reduction technique¶
Idea (and implementation) of LSI is very similar to PCA
- We want to compress sparse BOW-representation in to dense representation
- We want this representation to save as much initial information and be meaningful
Singular Value Decomposition (SVD)¶
Every matrix $A$ of size $n \times m$ and rank $r$ can be decomposed as: $$ A = U \Sigma V^\top ,$$ where
- $U$ - unitary matrix, consists of eigenvectors of $AA^\top$
- $V$ - unitary matrix, consists of eigenvectors of $A^\top A$
- $\Sigma$ - diagonal matrix with singular values $s_i = \sqrt{\lambda_i}$
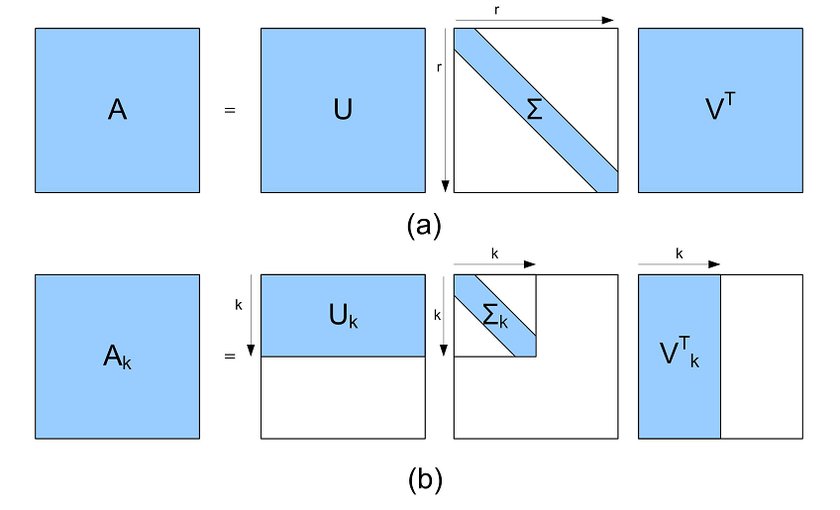
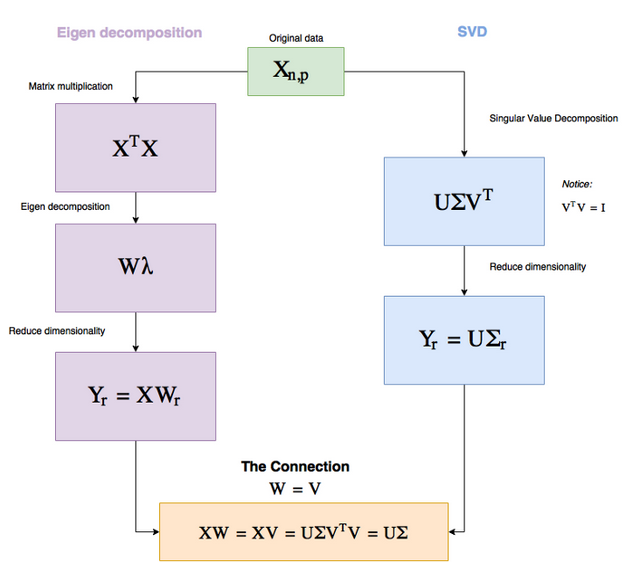
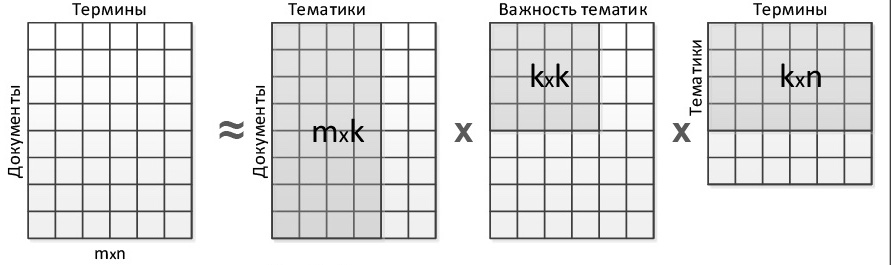
Pros
- Easy
- Can find similar words with $V$ and similar documents with $U$
- LSA in search task is called Latent Semantic Indexing
- Query $q$ is also some sequence of words
- How to we find most similar documents in corpus with LSI?
Pros
- Simple
- Can find similar words with $V$ and similar documents with $U$
- LSA in search task is called Latent Semantic Indexing
- Query $q$ is also some sequence of words
- Pass q through the same preprocessing as main text
- Make BOW representation of it
- Make LSI representation with $$ \hat{q} = qV\Sigma^{-1} $$
Cons
- Problems with interpretation
In [ ]:
from sklearn.decomposition import TruncatedSVD
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
texts = [
"Группа крови на рукаве",
"Мой порядковый номер на рукаве",
"Пожелай мне удачи в бою",
"Пожелай мне не остаться в этой траве",
"Не остаться в этой траве",
"Пожелай мне удачи"
]
In [ ]:
X = TfidfVectorizer(norm=None).fit_transform(texts, )
print(X.toarray().round(2))
In [ ]:
Z = TruncatedSVD(n_components=3).fit_transform(X)[:, 1:]
Z
In [ ]:
_, ax = plt.subplots(1,1)
ax.scatter(Z[:, 0], Z[:, 1])
ax.scatter(0,0)
for i, z in enumerate(Z):
ax.arrow(0., 0., z[0], z[1], width=0.001)
ax.text(z[0], z[1], texts[i])
- LSA is just some strange dimention-reduction algorithm which is applied to data
- If we consider topic modelling as a phenomenon - it is much deeper than simple compression
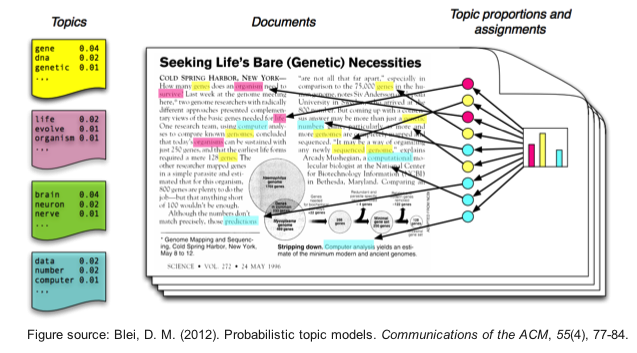
Probabilistic topic models¶
 </cetner>
</cetner>